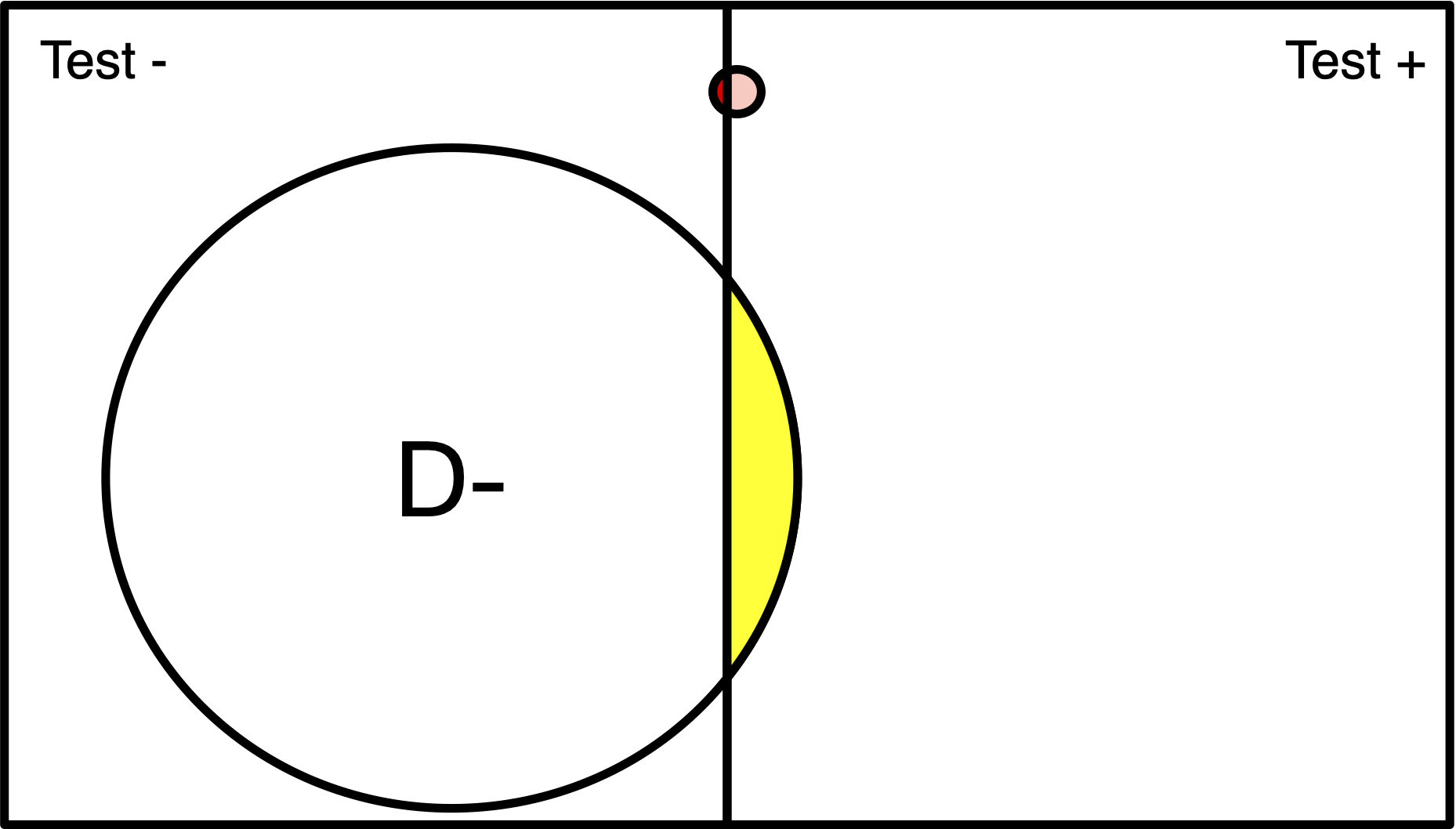
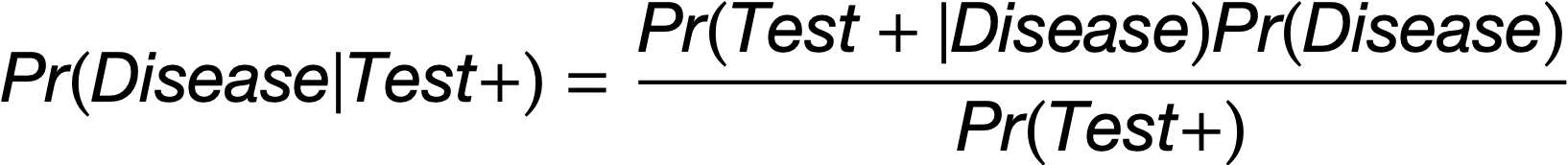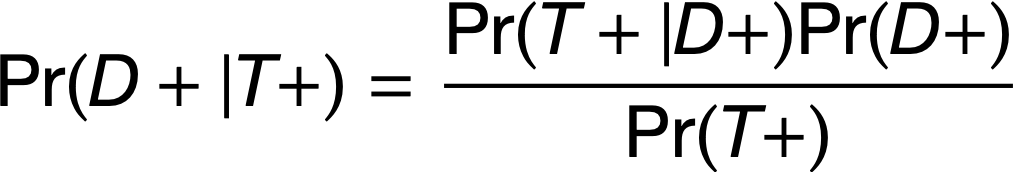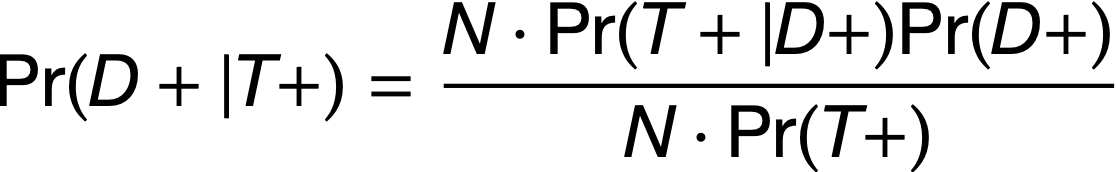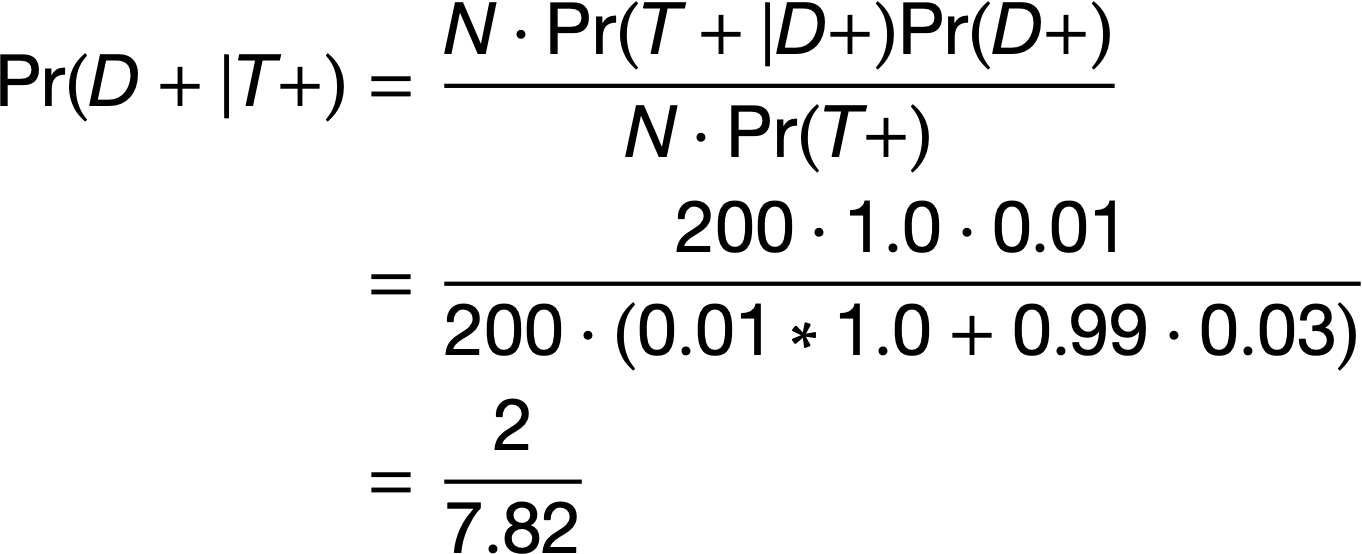What is the Probability of Disease Given A Positive Test?
Probability of Testing Positive if Have Disease
Probability of Having the Disease
Probability of a Positive Test
Bayes’ Theorem
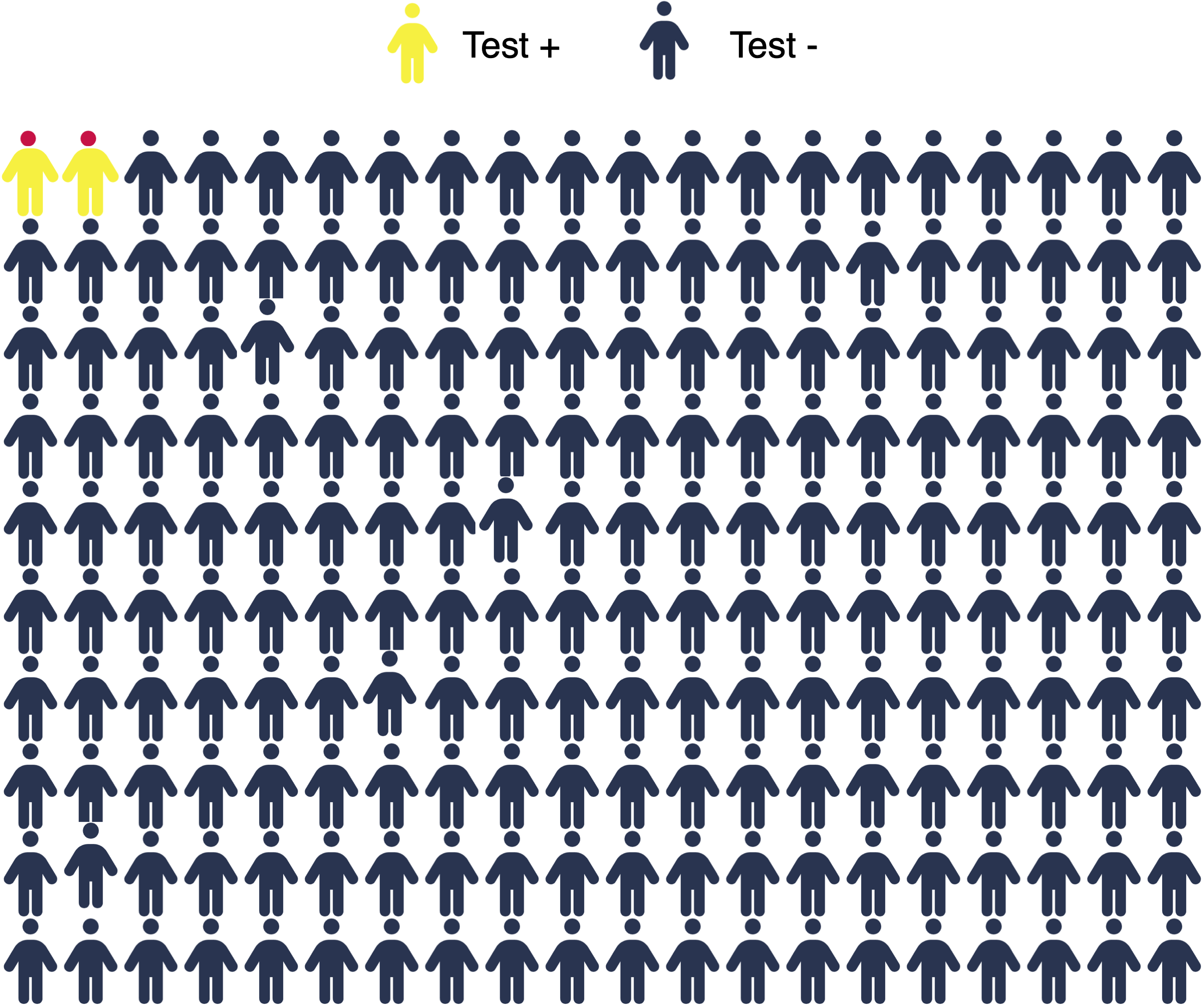
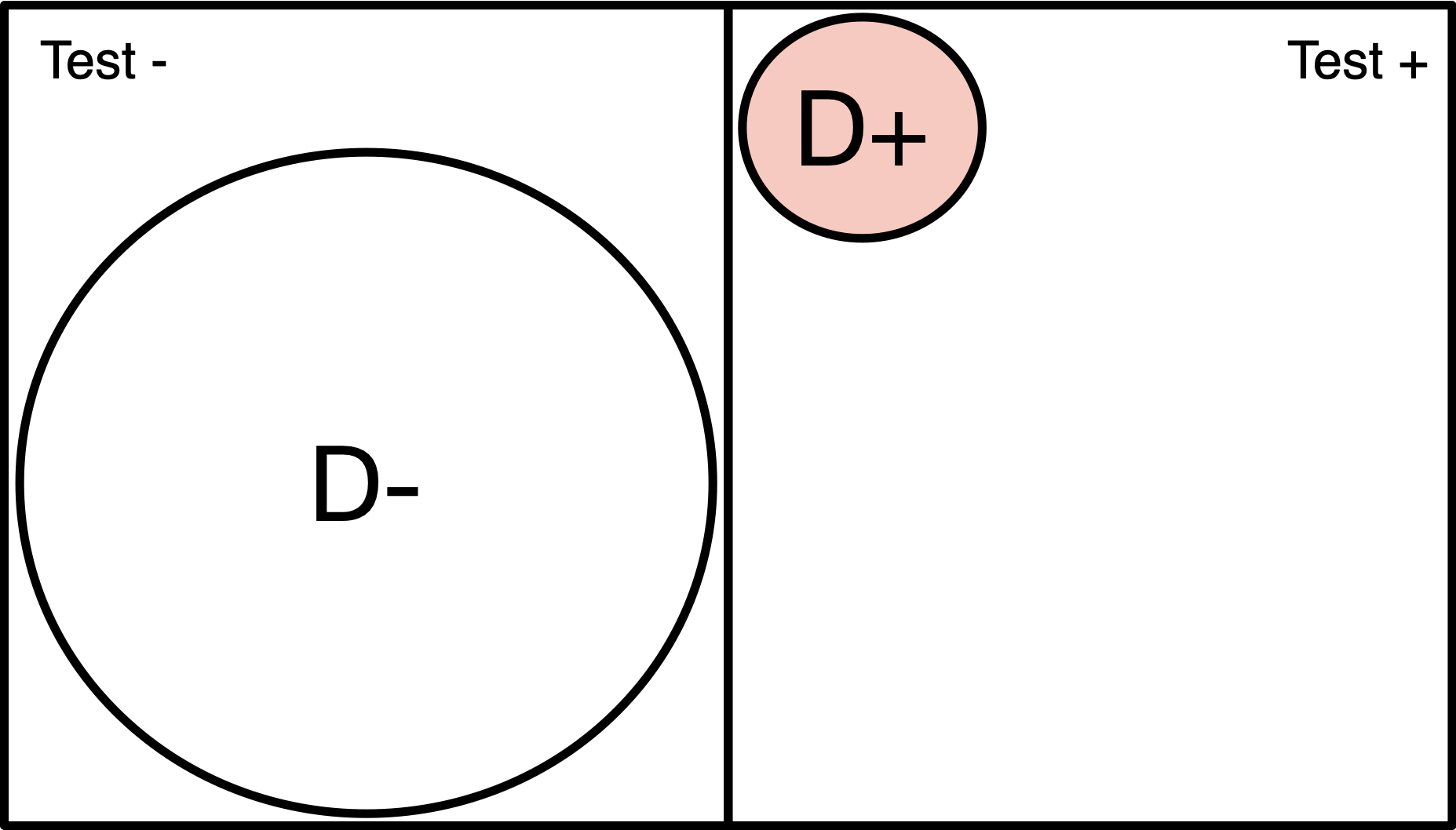
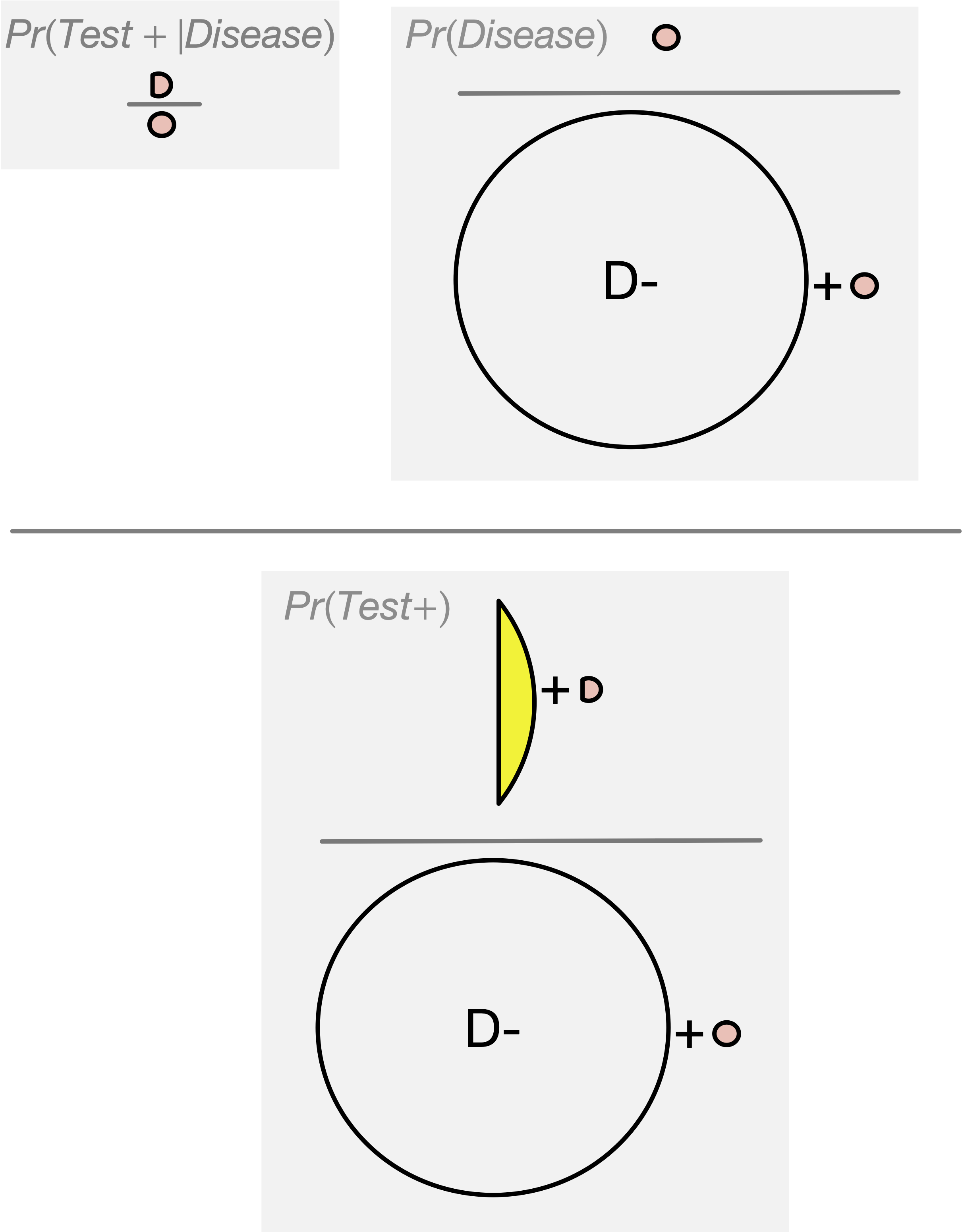
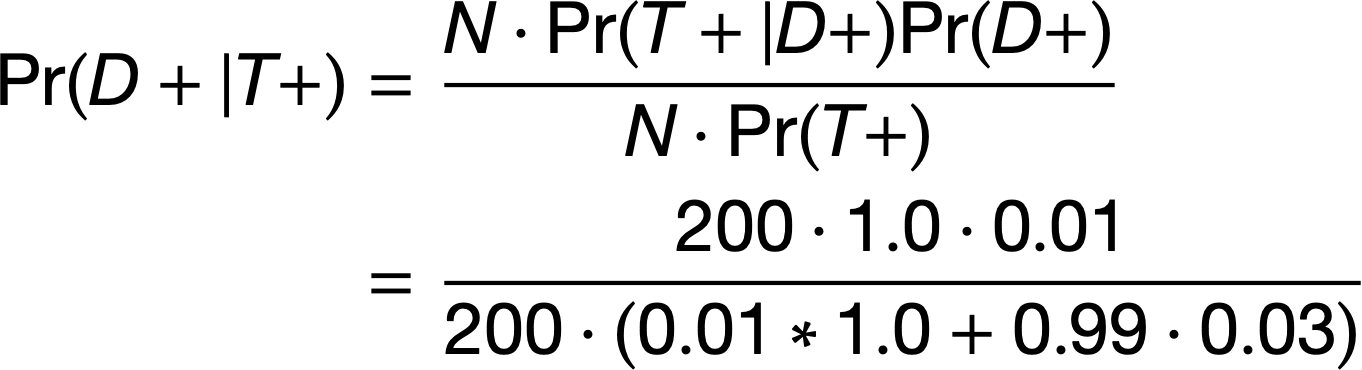
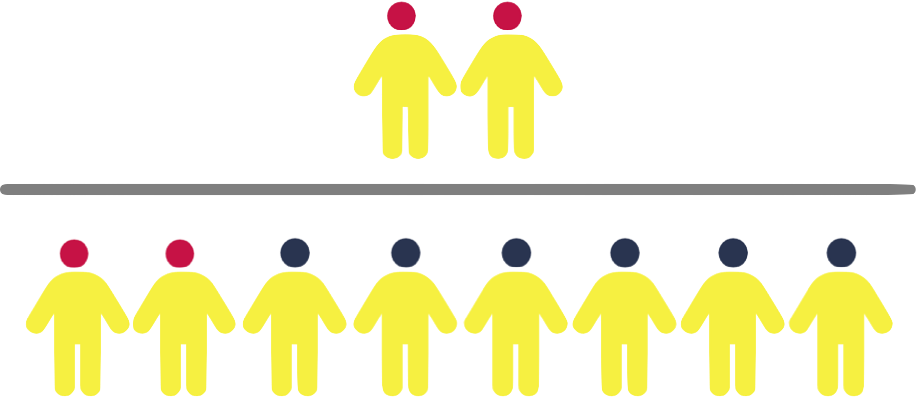
Population of 200
Disease (red) has 1% prevalence.
Test will detect 100% of positive cases.
3% of disease-free individuals will test positive
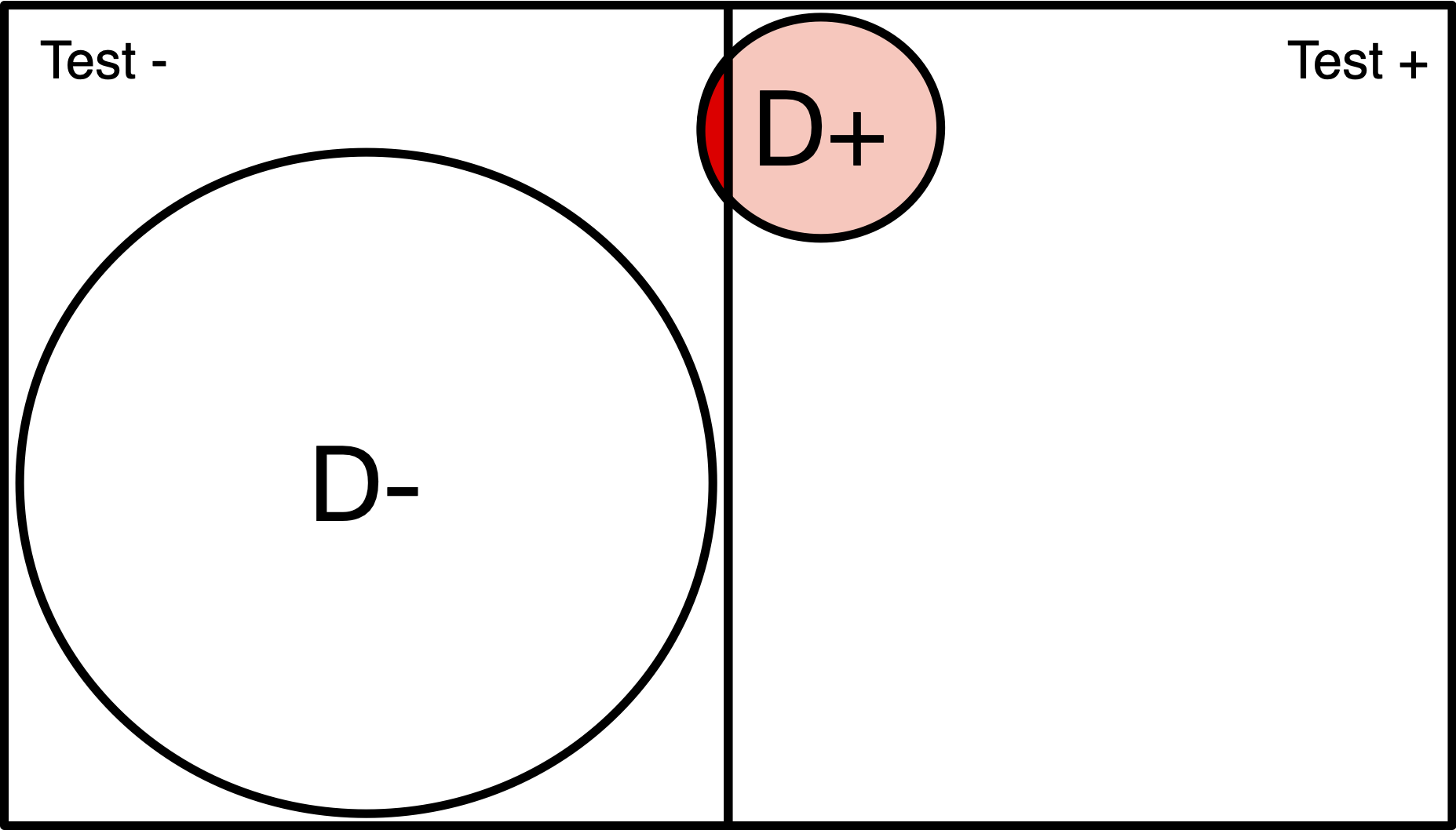
Population of 200
Disease (red) has 1% prevalence.
Test will detect 100% of positive cases.
3% of disease-free individuals will test positive
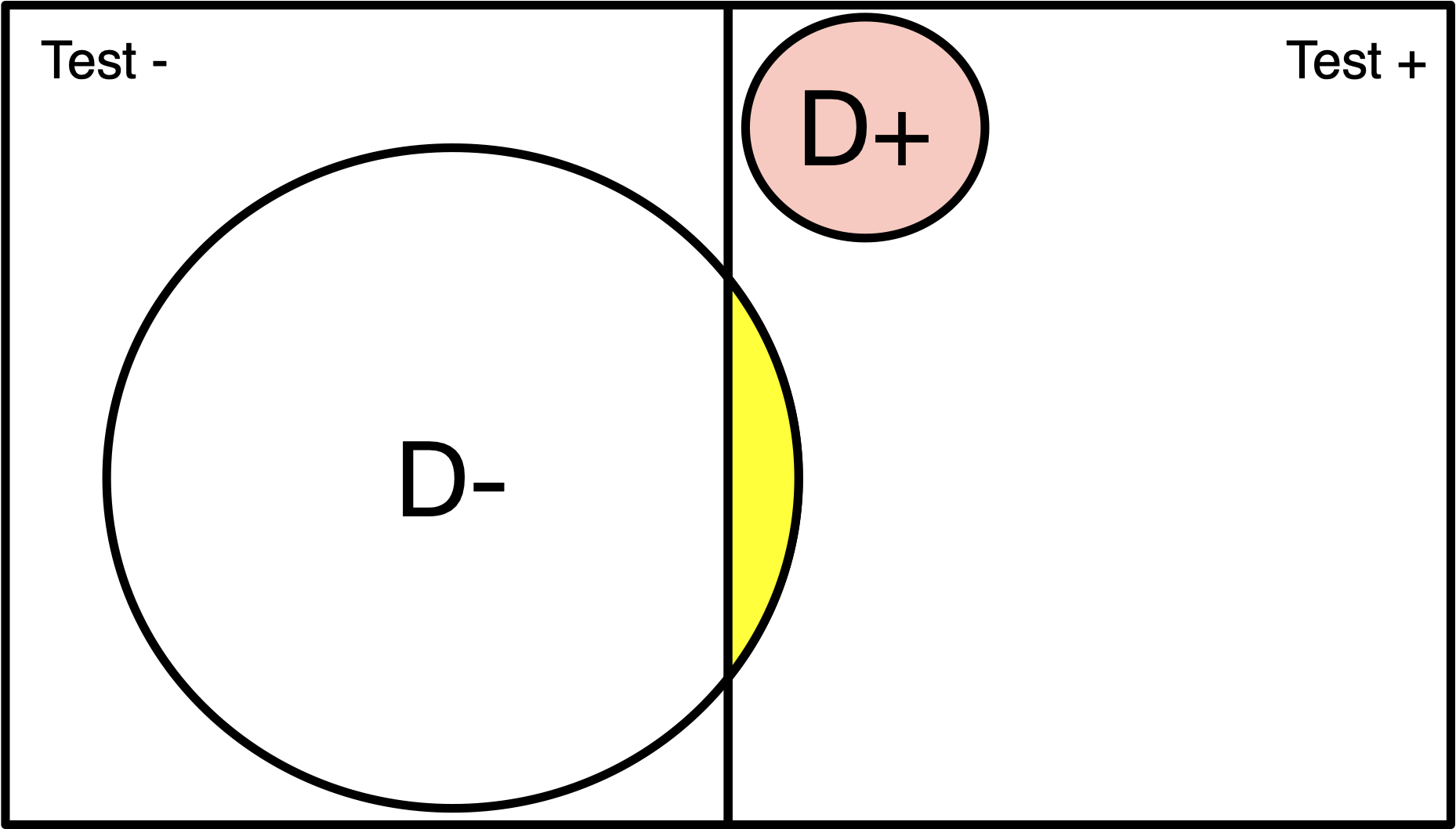
Population of 200
Disease (red) has 1% prevalence.
Test will detect 100% of positive cases.
3% of disease-free individuals will test positive
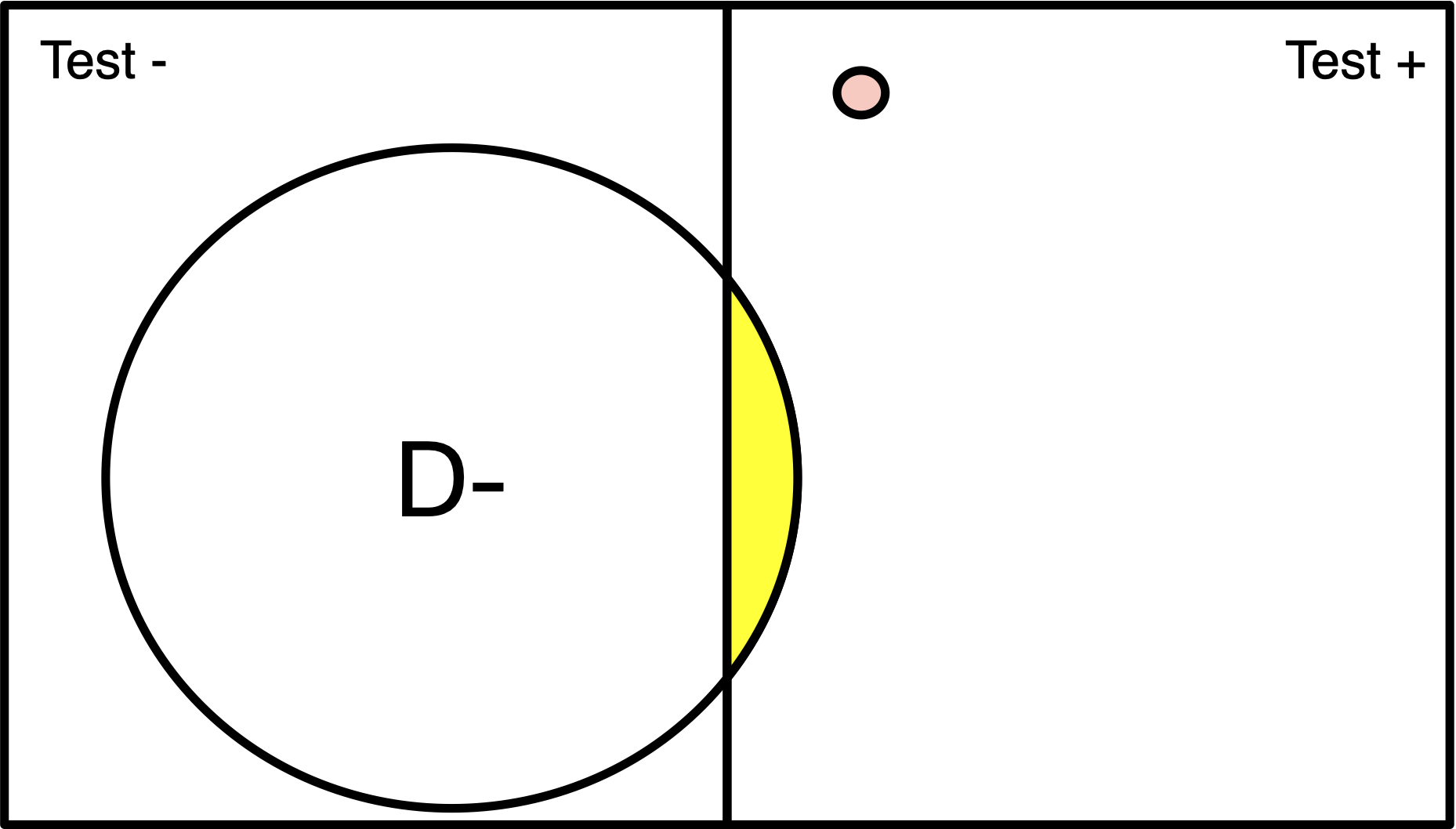
Population of 200
Disease (red) has 1% prevalence.
Test will detect 100% of positive cases.
3% of disease-free individuals will test positive
Population of 200
Disease (red) has 1% prevalence.
Test will detect 100% of positive cases.
3% of disease-free individuals will test positive
2. 2x2 Tables
2x2 Example: Disease Testing
Antibody
Diagnostic
Disease Testing
Case example
You are trying to determine what proportion of the population has already been exposed a new communicable disease, in hopes of figuring out if herd immunity is possible.
You decide to do a antibody test to measure the level of antibodies in a sample of 500 participants
Disease Testing
Case example
What is the test’s SENSITIVITY?
What is the test’s SPECIFICITY?
What is the test’s FALSE NEGATIVE RATE?
What is the test’s FALSE POSITIVE RATE?
Disease Testing
Case example
D+
D-
T+
a (TP)
b (FP)
a + b
T-
c (FN)
d (TN)
c + d
a + c
b + d
a + b + c + d
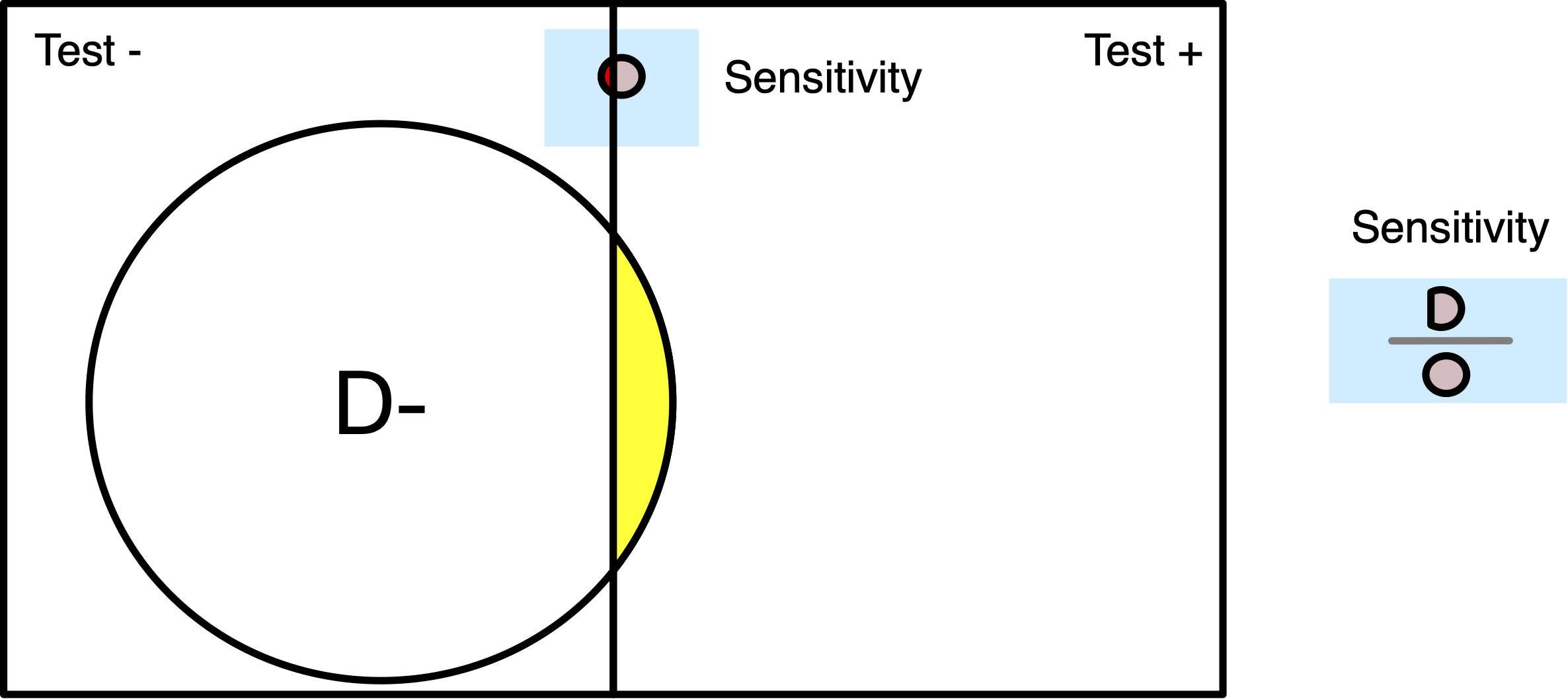
Disease Testing: SENSITIVITY
D+
D-
T+
125 (a, TP)
20 (b, FP)
145 (a + b)
T-
9 (c, FN)
346 (d, TN)
355 (c + d)
134 (a + c)
366 (b + d)
500 (a + b + c + d)
Test Sensitivity among those who have or had the virus, 125/134 = 93% (Interpretation: The probability of the screening test correctly identifying diseased subjects was 93%)
Disease Testing: SENSITIVITY
Example: SPECIFICITY
D+
D-
T+
125 (a, TP)
20 (b, FP)
145 (a + b)
T-
9 (c, FN)
346 (d, TN)
355 (c + d)
134 (a + c)
366 (b + d)
500 (a + b + c + d)
Test Specificity among those without the disease at any point, 346/366 = 95% (Interpretation: The probability of the screening test correctly identifying non-diseased subjects was 65%)
Disease Testing: SPECIFICITY
Do you want a test with good Sensitivity or good Specificity?
False Negatives
False negative rate (1-sensitivity) is the proportion of diseased people with a negative test: c/(a+c)
False Negatives
False negative rate (1-sensitivity) is the proportion of diseased people with a negative test: c/(a+c)
False Negatives
False Positives
False positive rate (1-specificity) is the proportion of non-diseased people with a positive test: b/(b+d)
False Negatives
False positive rate (1-specificity) is the proportion of non-diseased people with a positive test: b/(b+d)
False Negatives
2x2 Example: Disease Testing
Antibody
Diagnostic
Predictive value
…Imagine you are discussing the results of a screening test with a patient
(+) If the patient has an abnormal screening test (i.e. it’s POSITIVE), how likely is it that he really has the disease? [how worried should he be?]
(-) If the test was NEGATIVE, how likely is it that he really does not have the disease? [how reassured should he be?]
Positive Predictive Value
Direct application of Bayes’ theorem
The probability that a person with a positive test result is truly diseased, i.e., Pr(D+|T+)
Formula:
Positive Predictive Value
Direct application of Bayes’ theorem
The probability that a person with a positive test result is truly diseased, i.e., Pr(D+|T+))
PPV: How many of test positives are true positives?
Heart Attack:
Present
Absent
Elevated (+)
300 (a, TP)
15 (b, FP)
315 (a + b)
Normal (-)
35 (c, FN)
150 (d, TN)
185 (c + d)
335 (a + c)
165 (b + d)
500 (a + b + c + d)
315 patients in this coronary care unit had “elevated” screening levels; out of those 315, 300 had heart attacks. Of those with “elevated” screening levels, what proportion have had a heart attack?PPV = 300/315 = 95%
Negative Predictive Value
Direct application of Bayes’ theorem
The probability that a person with a negative test result is truly non-diseased, i.e., Pr(D-|T-))
Negative Predictive Value
Direct application of Bayes’ theorem
The probability that a person with a negative test result is truly non-diseased, i.e., Pr(D-|T-))
NPV: How many of test negatives are true negatives?
Present
Absent
Elevated (+)
300 (a, TP)
15 (b, FP)
315 (a + b)
Normal (-)
35 (c, FN)
150 (d, TN)
185 (c + d)
335 (a + c)
165 (b + d)
500 (a + b + c + d)
185 patients in this coronary care unit had normal screening levels; out of those 185, 150 did not have heart attacks. Of those with “normal” screening levels, what proportion did not have heart attacks?NPV = 150/185 = 81%
Predictive values
Predictive values are highly dependent on the prevalence of disease in a sample (whereas prevalence theoretically should NOT impact sensitivity or specificity)
Previously, we had a population of 500 patients in a coronary care unit, most of whom were having heart attacks.
Now, let’s switch to a different sample
- Around 2,100 patients are coming into the ER with chest pain, but most don’t have heart attacks (slightly over 15% have heart attacks)
Different sample…
Present
Absent
Elevated (+)
300 (a, TP)
160 (b, FP)
460 (a + b)
Normal (-)
35 (c, FN)
1640 (d, TN)
1675 (c + d)
335 (a + c)
1800 (b + d)
2135 (a + b + c + d)
When we have a different sample, one that has less disease, the PPV falls & the NPV goes up
Before:
Present
Absent
Elevated (+)
300 (a, TP)
15 (b, FP)
315 (a + b)
Normal (-)
35 (c, FN)
150 (d, TN)
185 (c + d)
335 (a + c)
165 (b + d)
500 (a + b + c + d)
Different sample…
PPV = 300 / 460 (460 people with “elevated levels” in this sample, only 300 of them are having heart attacks) = 65% (95% in previous sample)
NPV = 1,640 / 1,675 (Of those with “normal levels,” most are not having heart attacks) = 98% (81% in previous sample)
PPV / NPV
On a screening test, a high PPV is acceptable, implying that false positive outcomes are minimized, under a variety of circumstances:
When, relative to potential benefits, the costs are high (time/personnel/inconvenience/anxiety/discomfort)
Risk of harm from follow-up diagnoses or therapy (such as infection) is high despite the benefits from treatment also being high
Reference: Trevethan (2017)
PPV / NPV
A moderate PPV is acceptable when:
False positive outcomes might be “okay” if follow-up tests are inexpensive, easily and quickly performed, and not stressful for clients.
If no harm is likely to be done to clients in protecting them against a target condition even if that condition is not present
Reference: Trevethan (2017)
PPV / NPV
A high NPV is acceptable, implying that false negatives are minimized, under a different set of circumstances:
Quickly progressing diseases, conditions that are not contagious, or those that require treatment early in its course
PPV / NPV
A high NPV is acceptable, implying that false negatives are minimized, under a different set of circumstances:
Quickly progressing diseases, conditions that are not contagious, or those that require treatment early in its course
A moderate NPV could be acceptable when:
Condition is not serious or contagious or does not progress quickly
Dx of condition is ambiguous and subsequent screening tests can be easily scheduled or the condition is likely to resolve without treatment
Reference: Trevethan (2017)
Prevalence and test characteristics
Generally:
PPV and NPV are dependent on prevalence (Pre-Test Probability)
SENS + SPEC are usually not dependent on prevalence (spectrum/case-mix bias)
Prevalence and test characteristics
Generally:
PPV and NPV are dependent on prevalence (Pre-Test Probability)
SENS + SPEC are usually not dependent on prevalence (spectrum/case-mix bias)
Spectrum bias – Performance of a test may vary in different clinical settings/different mix of patients
Predictive values
The pretest (or prior) probability of disease in the 2x2 table before any testing
= Probability of the presence of the target disease conditional on the available information prior to performing the test under consideration
In other words, the proportion of the total population with the disease: (a+c)/(a+b+c+d). This is disease prevalence
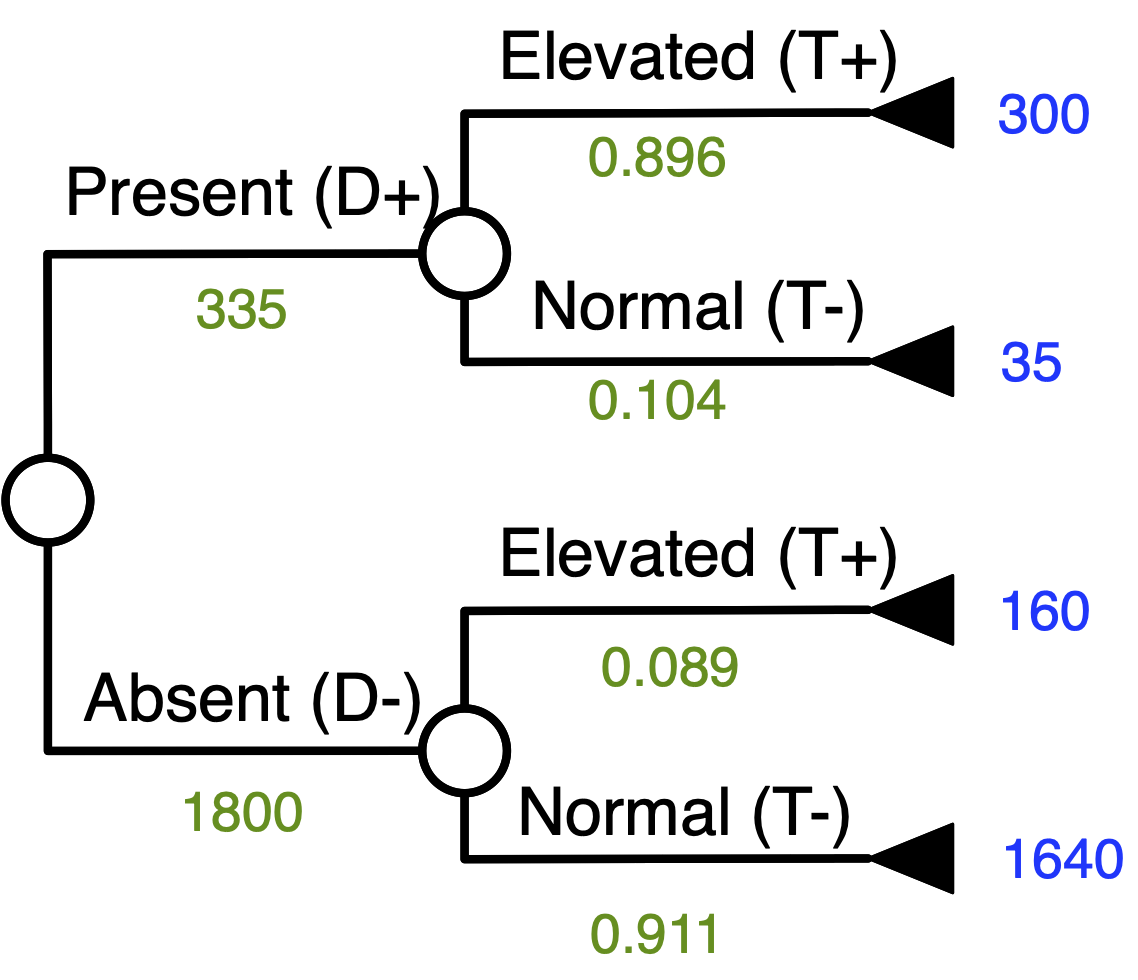
Latter sample
Present
Absent
Elevated (+)
300 (a, TP)
160 (b, FP)
460 (a + b)
Normal (-)
35 (c, FN)
1640 (d, TN)
1675 (c + d)
335 (a + c)
1800 (b + d)
2135 (a + b + c + d)
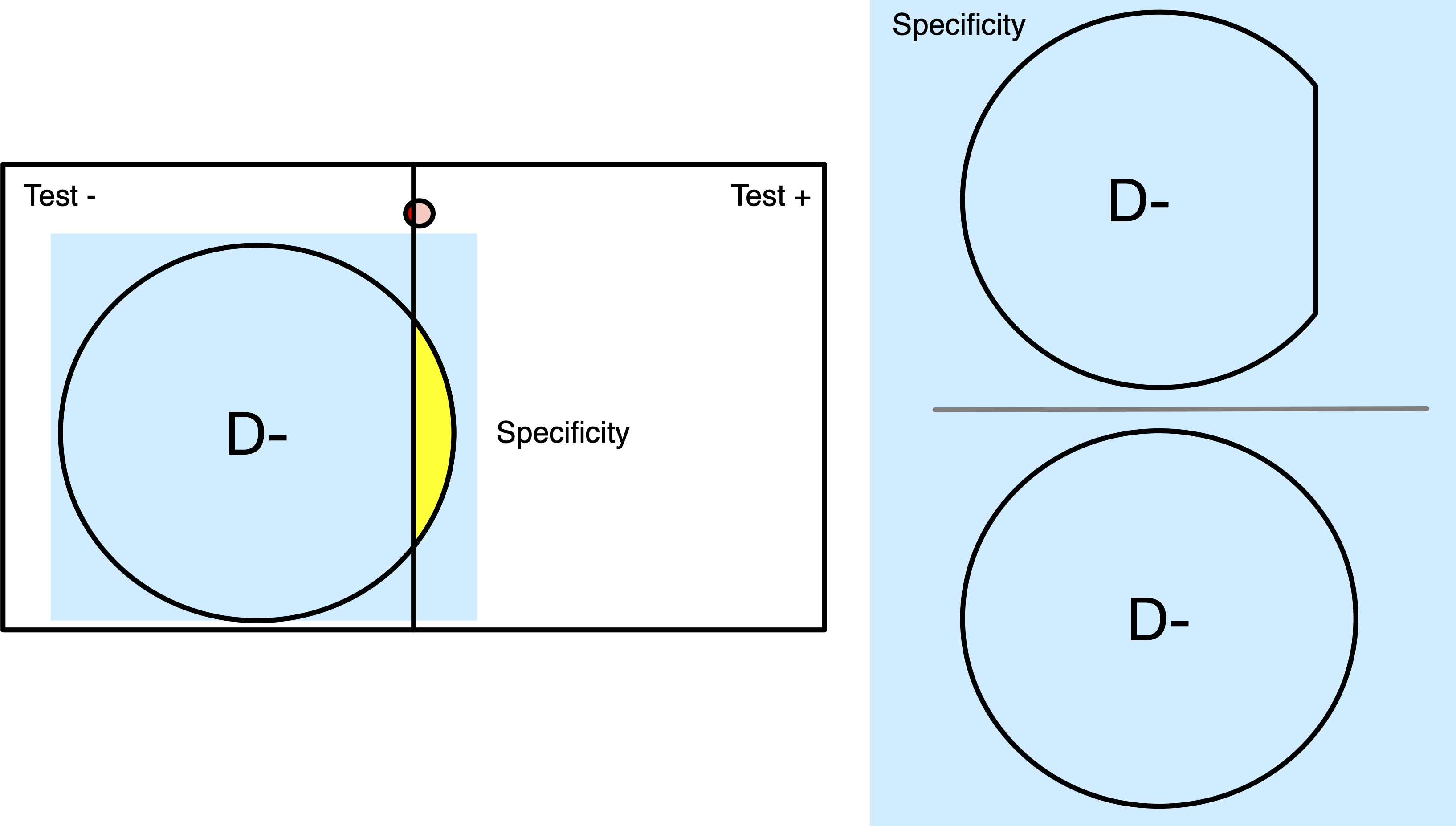
Disease Prevalence
= (a+c) / (a+b+c+d) = 335 / 2,135 = 0.16
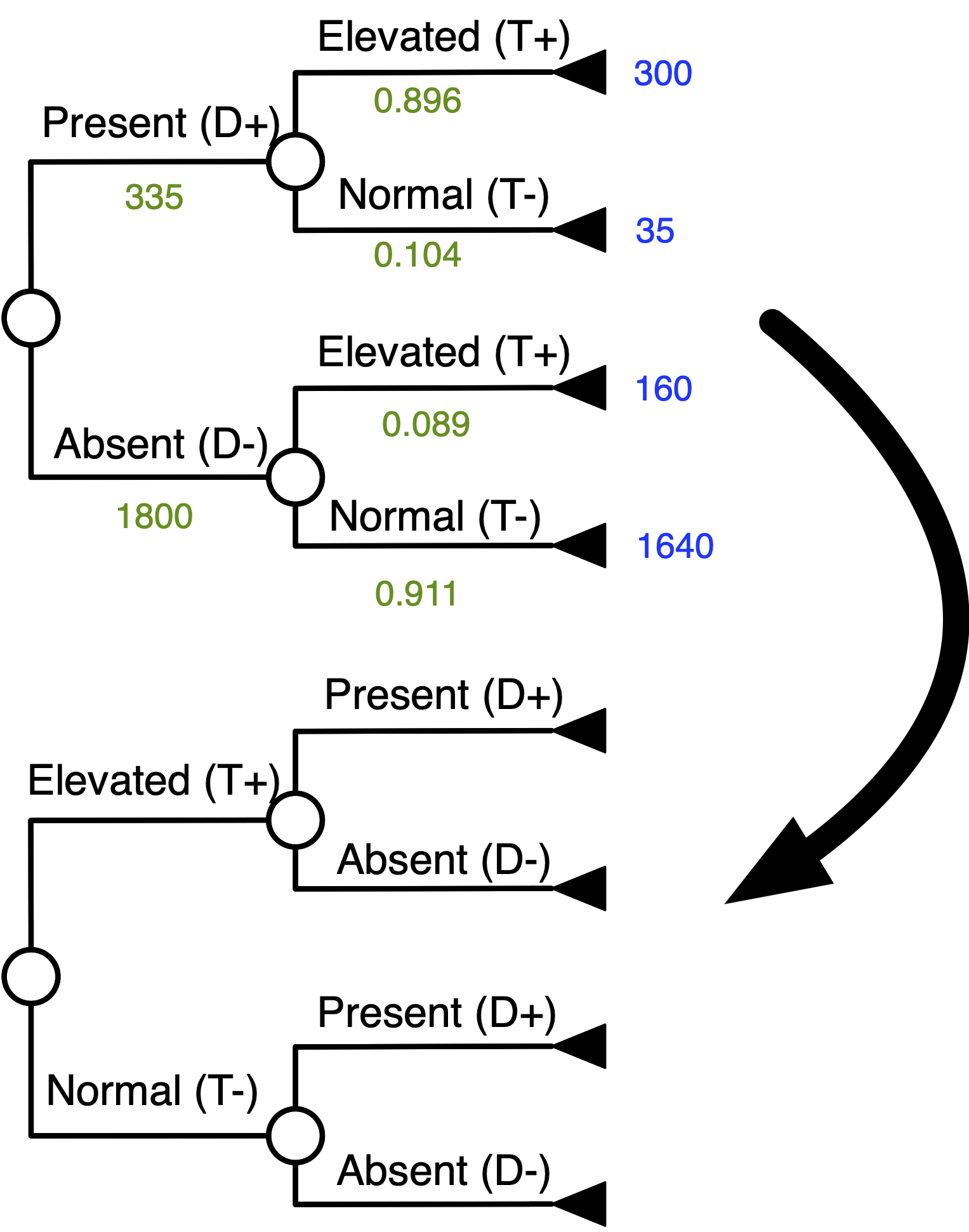
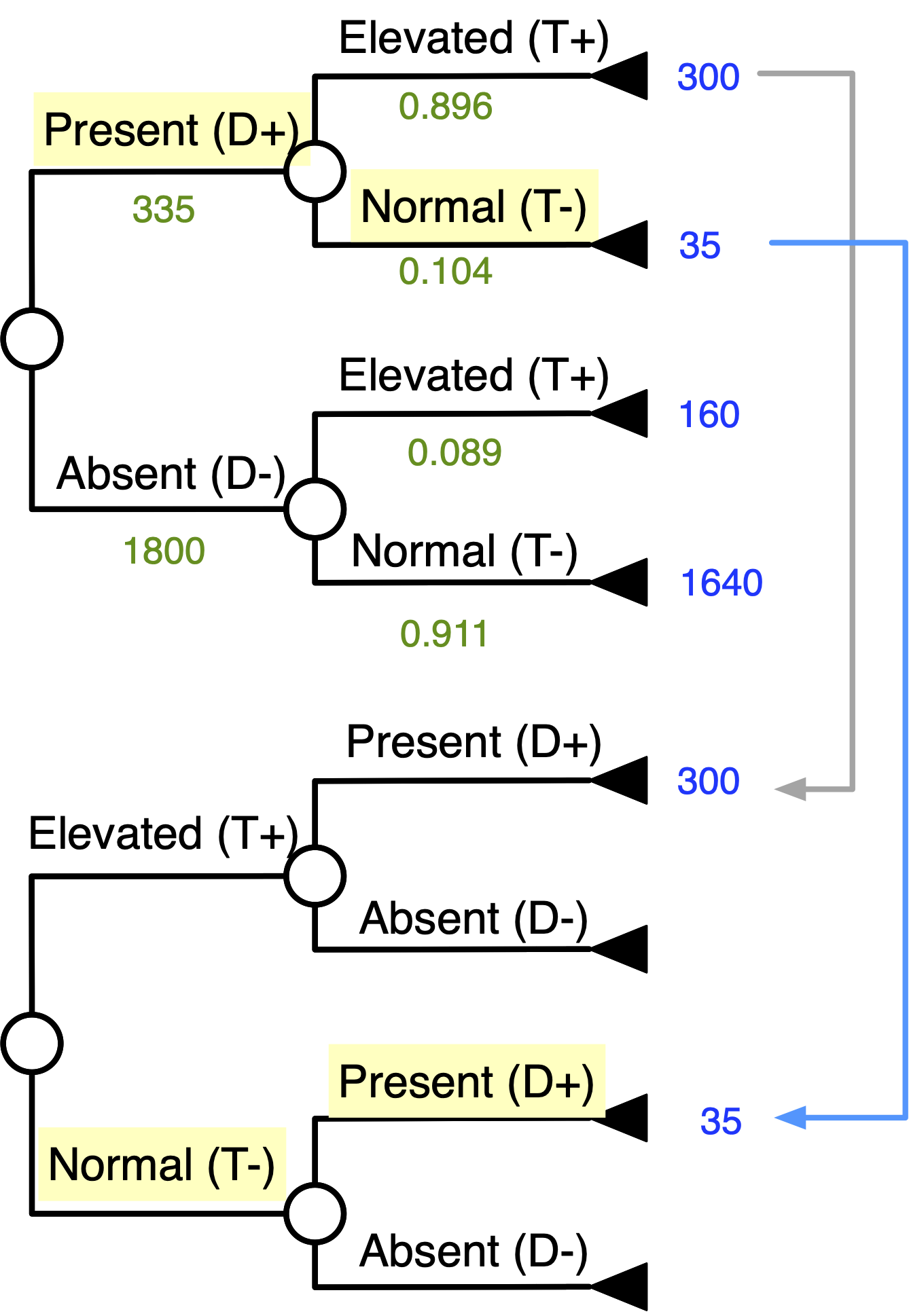
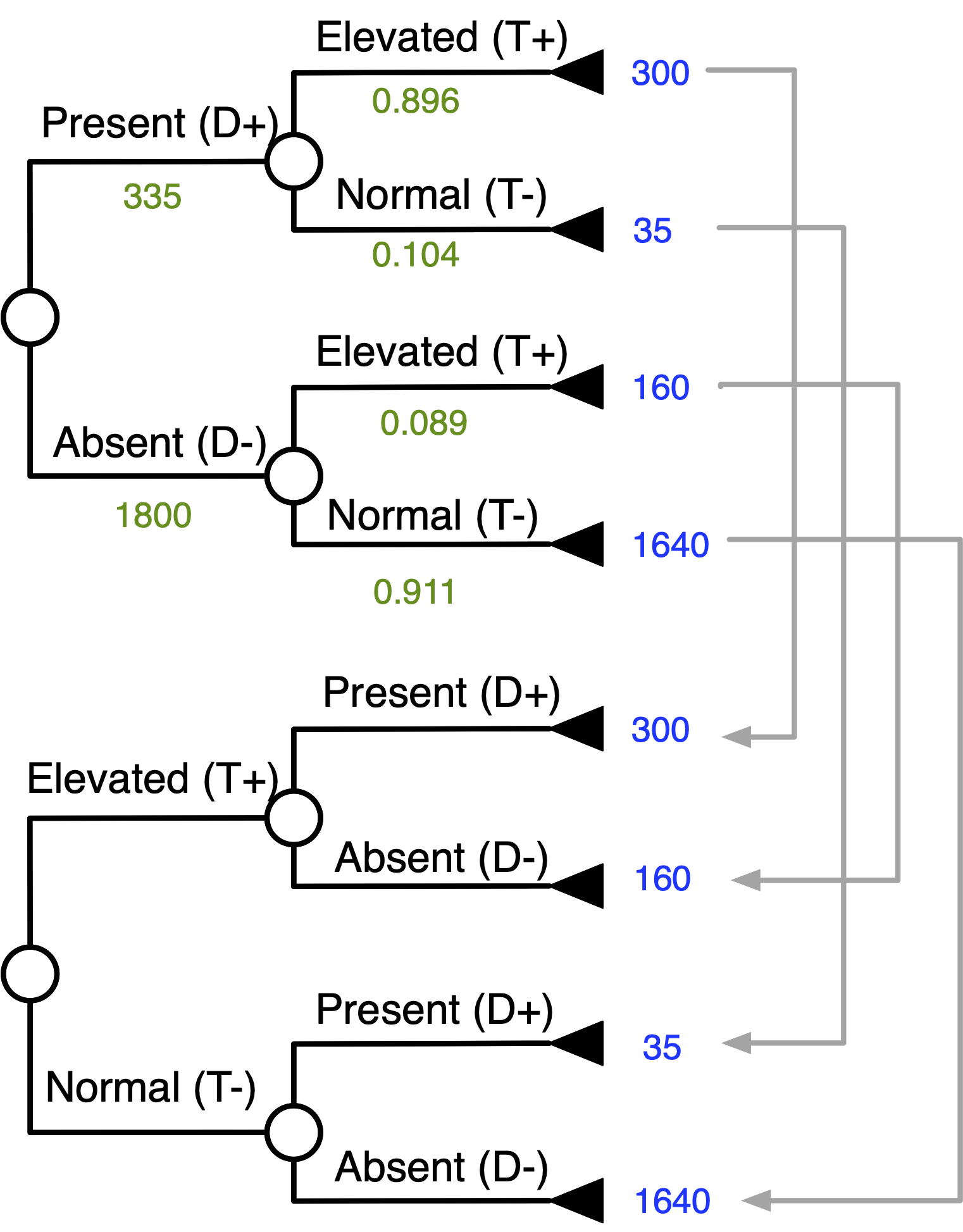
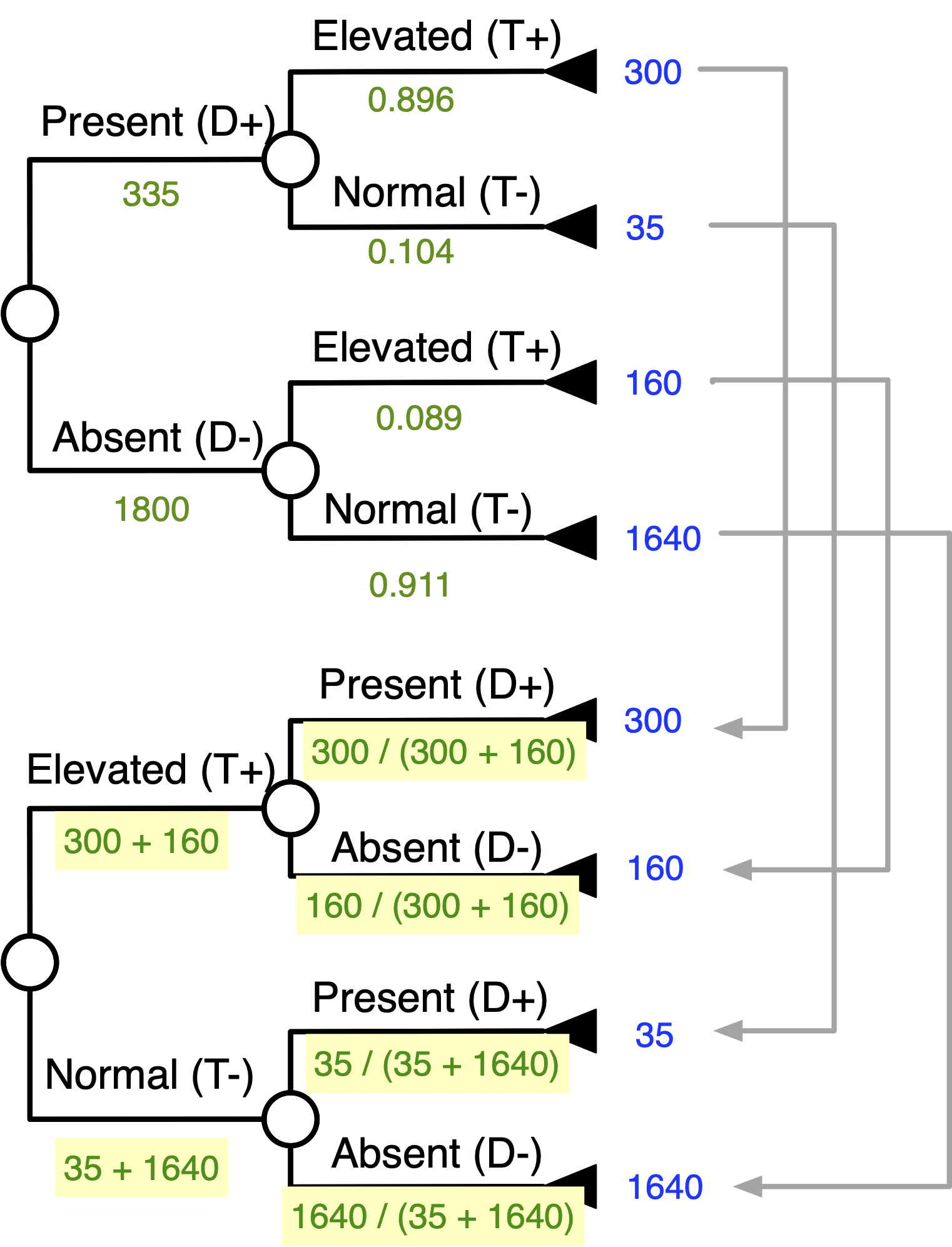
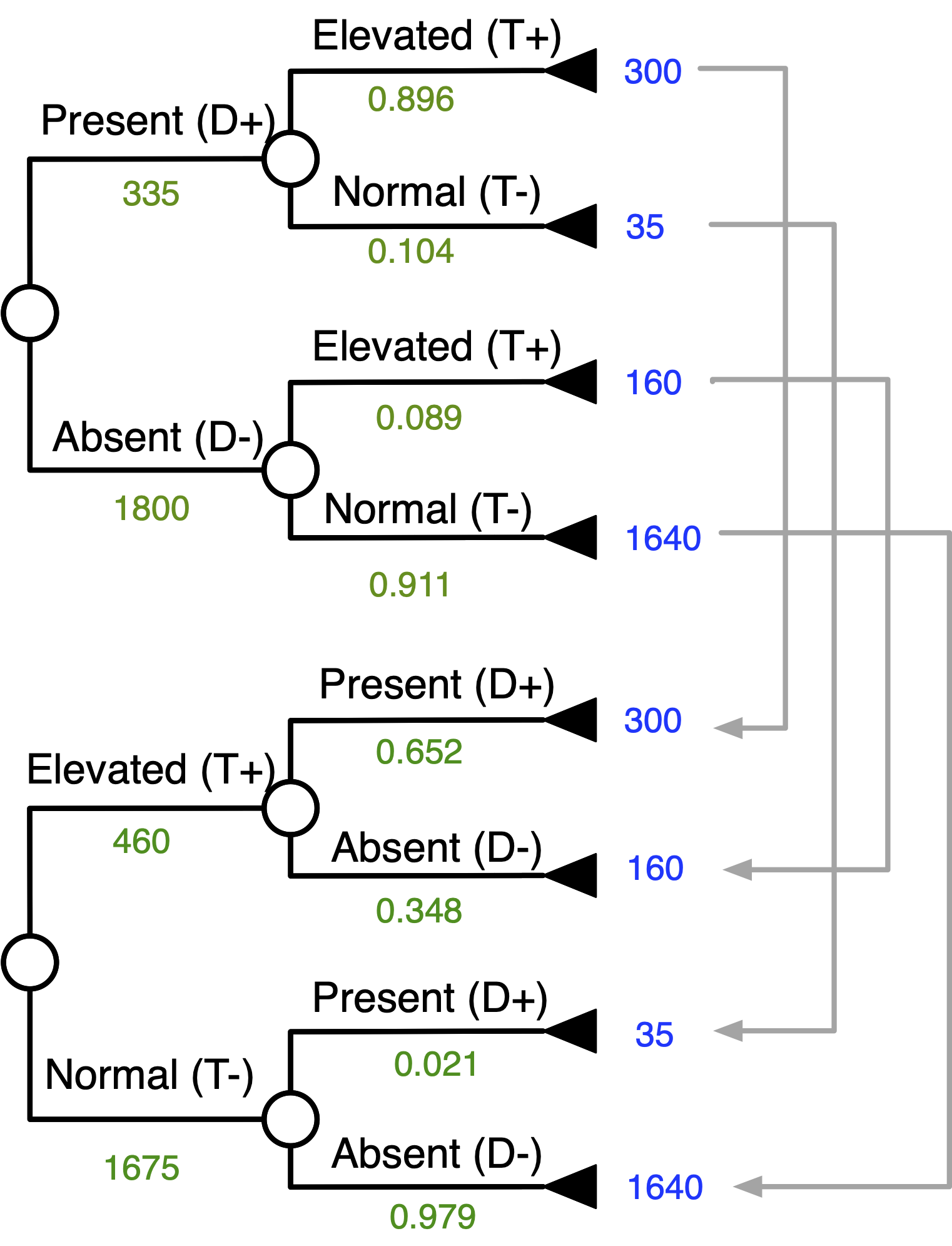
Bayes’ Theorem With Tree Inversion
Bayes’ theorem with tree inversion
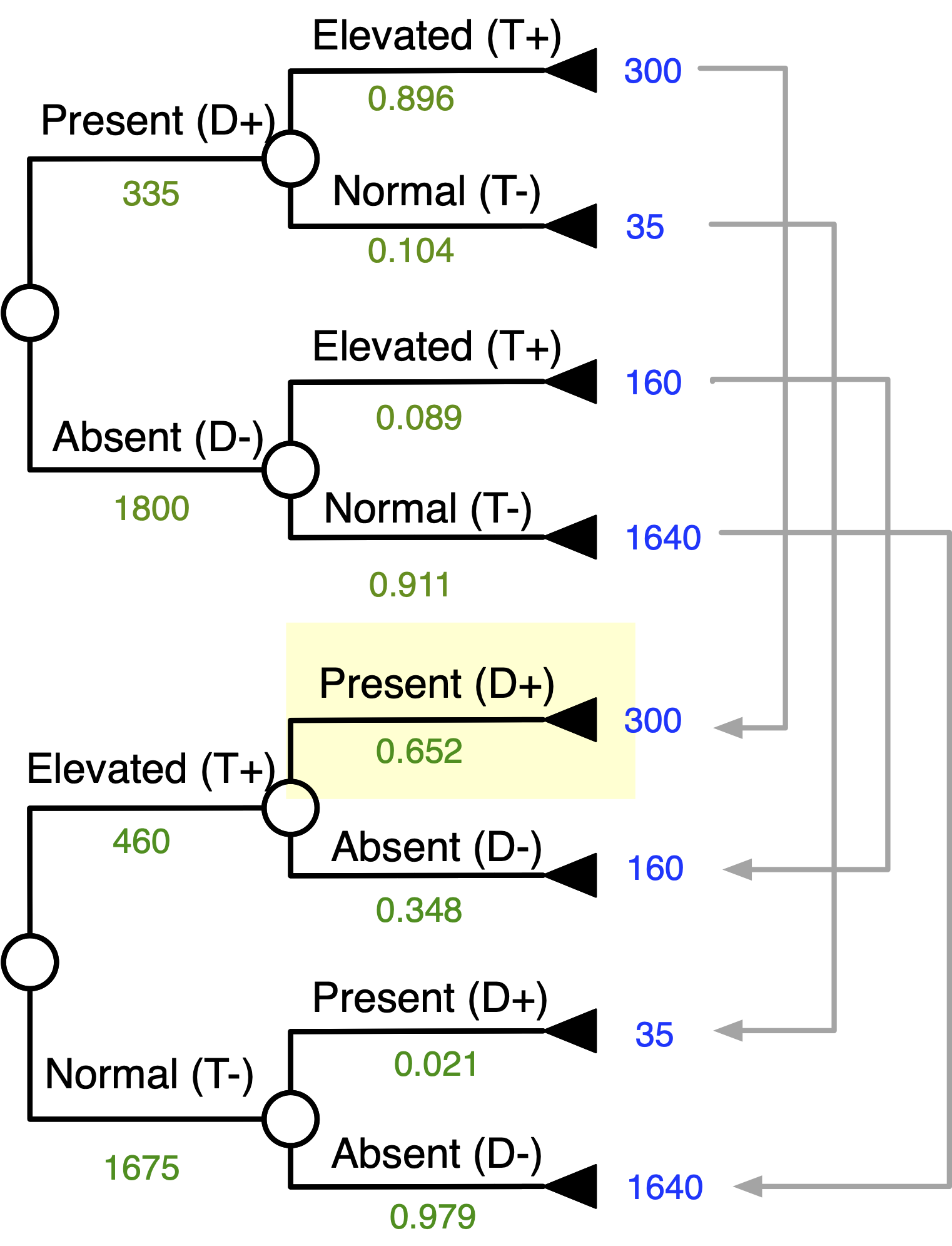
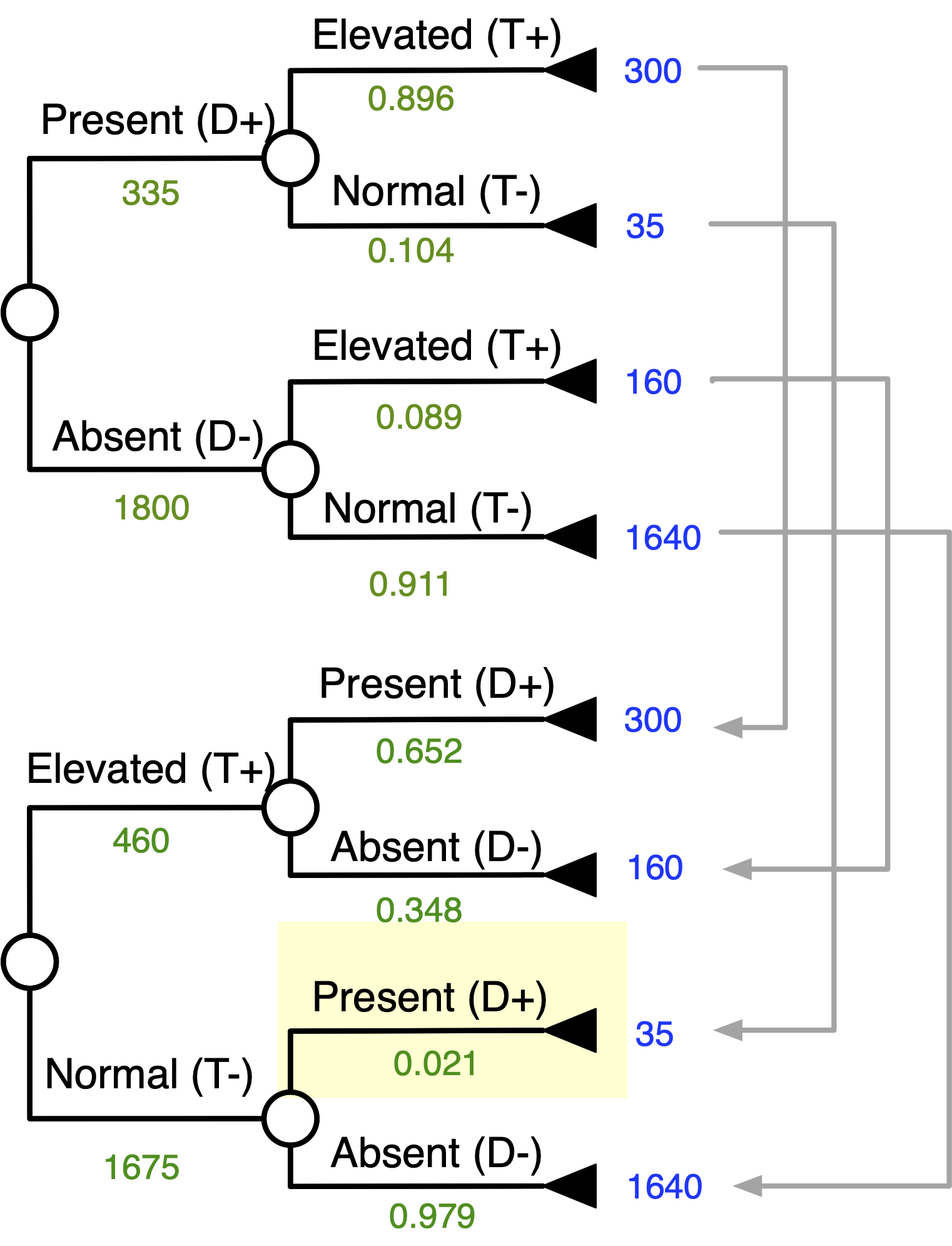
Goal: “Flip” The Tree
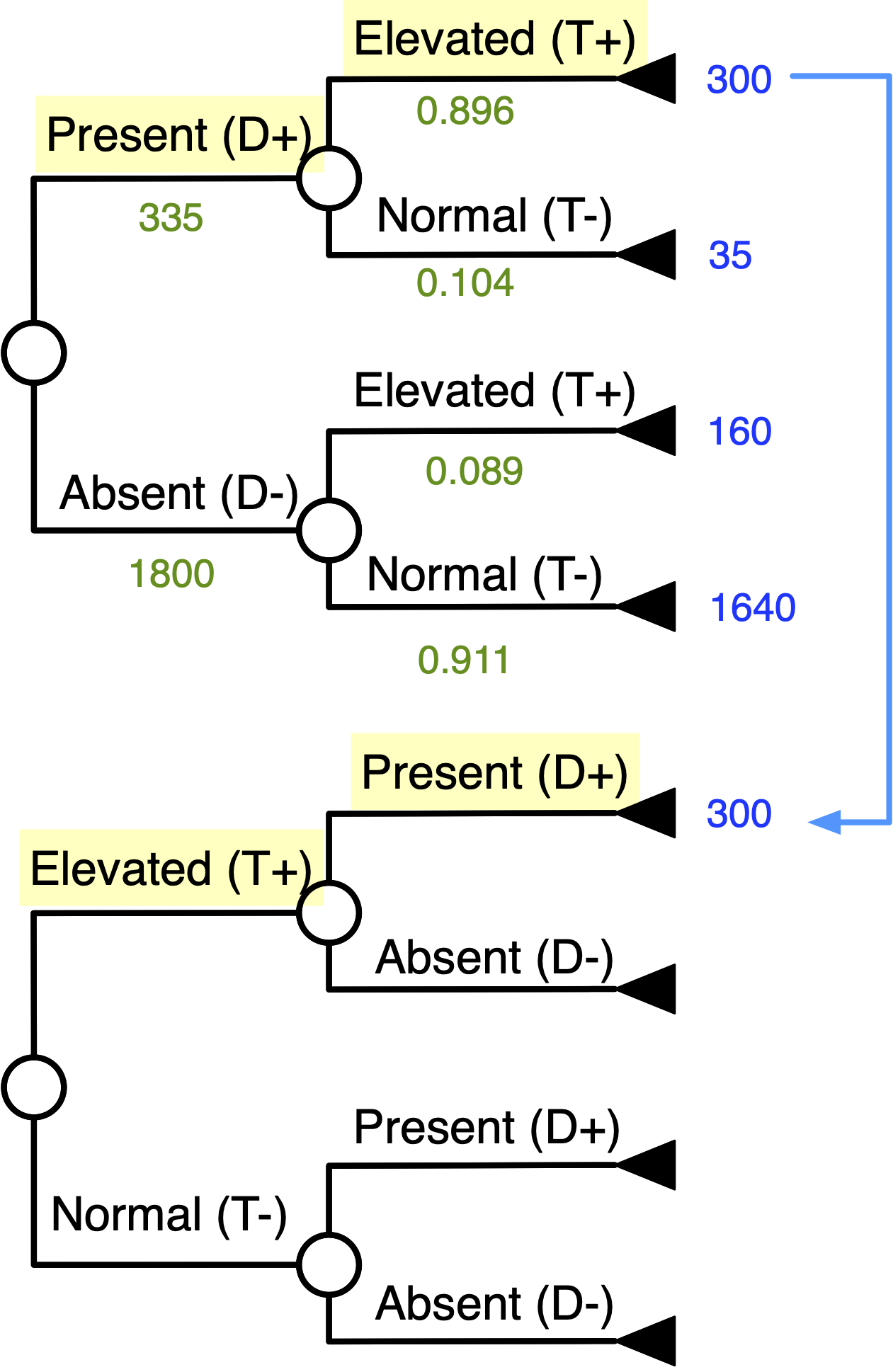
Start Matching Terminal Numbers …
Continue Matching Terminal Numbers …
Continue Matching Terminal Numbers …
Work Your Way Down the Tree …
Inverted Tree
Probability of Disease Given + Test
Probability of Disease Given - Test
Conclusions
We are often bayesian in how we think
Knowledge of test characteristics can help you to make more informed decisions
In general, diagnostic tests are helpful when pre-test prob is in the middle (30-70%) and test is going to move you past a decision threshold
Tests with very good characteristics (ex. 100% sens or spec) can also be very useful if used appropriately
[Extra] Likelihood Ratios
Likelihood ratio
Useful for situations in which a quick estimate of revised probabilities is needed
Likelihood that a given test result would be expected in a patient with the target disorder Pr(test result | D+) compared to the likelihood that the same result would be expected in a patient without the target disorder Pr(test result | D-) [A RATIO]
Likelihood ratios
The likelihood ratio (LR) summarizes test sensitivity and specificity into one number:
LR (positive test) = sensitivity/1-specificity (or TPR/FPR)
LR (negative test) = 1-sensitivity/specificity (or FNR/TNR)
Likelihood ratios
LR can be used to revise disease probabilities using the following form of Bayes’ Theorem:
Post-test odds = Pretest odds x LR
The odds that the patient has the target disorder, after the test results are known. It is calculated by multiplying the pre-test odds by the likelihood of a positive or negative test.
Likelihood ratios
LR’s are an advance beyond 2x2 tables
To use likelihood ratios, you must be comfortable converting between probabilities of disease and odds of disease
Odds are simply another way of describing the chances that something will (or won’t) happen
Likelihood ratios
Odds of Disease = \frac{\text{Probability}}{\text{1 - Probability}}
Probability = \frac{\text{Odds}}{\text{Odds + 1}}
Likelihood ratios
Odds favoring an event; Odds = p/(1-p) If an event has 0.20 probability of occurrence, the odds favoring the event = 0.2/0.8 = 0.25 (or 1:4)
Odds against (OddA) the event; OddA = (1-p)/p The odds against are 0.8/0.2 = 4 (or 4:1)
Back to first example (coronary care unit)
Present
Absent
Elevated (+)
300 (a, TP)
15 (b, FP)
315 (a + b)
Normal (-)
35 (c, FN)
150 (d, TN)
185 (c + d)
335 (a + c)
165 (b + d)
500 (a + b + c + d)
Pre-test probability was 67% (prevalence)
SENS = 0.90 & SPEC = 0.91
LR+ (for positive test result) = SENS / 1=SPEC = 0.90/1-0/.91 = 10
Interpretation: A patient with a positive test result is 10X more likely to have had a heart attack than someone who did not have a heart attack with the same test result
Back to first example (coronary care unit)
LR - (for a negative test result):
1-SENS / SPEC = 1-0.90 / 0.91 = .11, indicates a ~10-fold decrease in the odds of having a condition in a patient with a negative test result.
Back to first example (coronary care unit)
Pre-test probability
Pre-test odds (0.67 / 1-0.67)
Post (+ test) odds of disease = pre-test odds * LR(+)
Post (+ test) prob of disease = post-test odds / post-test odds + 1
Post (- test) odds of disease = pre-test odds * LR(-)
Post (- test) prob of disease = 0.22 / 1.22
Odds Likelihood Form of Bayes
Odds LR = \frac{\text{Pr(D+ | test result)}}{\text{Pr(D- | test result)}} = \frac{{Pr(D+)}}{Pr(D-)} * \frac{{lr(D+)}}{lr(D-)}
\frac{{Pr(D+)}}{Pr(D-)} * \frac{{lr(D+)}}{lr(D-)}
The above is the same as:
\frac{\text{Pr(D+ | test result)}}{\text{Pr(D- | test result)}}
Odds Likelihood Form of Bayes
Odds LR = \frac{\text{Pr(D+ | test result)}}{\text{Pr(D- | test result)}} = \frac{{Pr(D+)}}{Pr(D-)} * \frac{\text{Pr(test result | D+)}}{\text{Pr (test result | D-)}}
Pre-test odds favoring disease (the prior):
\frac{{Pr(D+)}}{Pr(D-)}
The post-test odds given the test result:
\frac{\text{Pr(D+ | test result)}}{\text{Pr(D- | test result)}}
Odds Likelihood Form of Bayes
\frac{\text{Pr(test result | D+)}}{\text{Pr (test result | D-)}} = \frac{{Pr(D-)}}{{Pr (D+)}} * \frac{{(CTN - CFP)}}{(CTP - CFN)}
How to calculate an optimal “cut-off” for a test with categorical or continuous results at the point in which we will optimize the cut-off conditional on the (1) prior probability of disease and (2) the consequences of the scenario we are assessing
Next lecture: Positivity Criterion!
Likelihood ratios
LR (+) GT 10 Excellent 5-10 Good 2-5 Fair. May be helpful 1-2 Unlikely to be helpful
LR (-) <0.1 Excellent 0.1-0.2 Good 0.2-0.5 Fair. May be helpful 0.5-1.0 Unlikely to be helpful