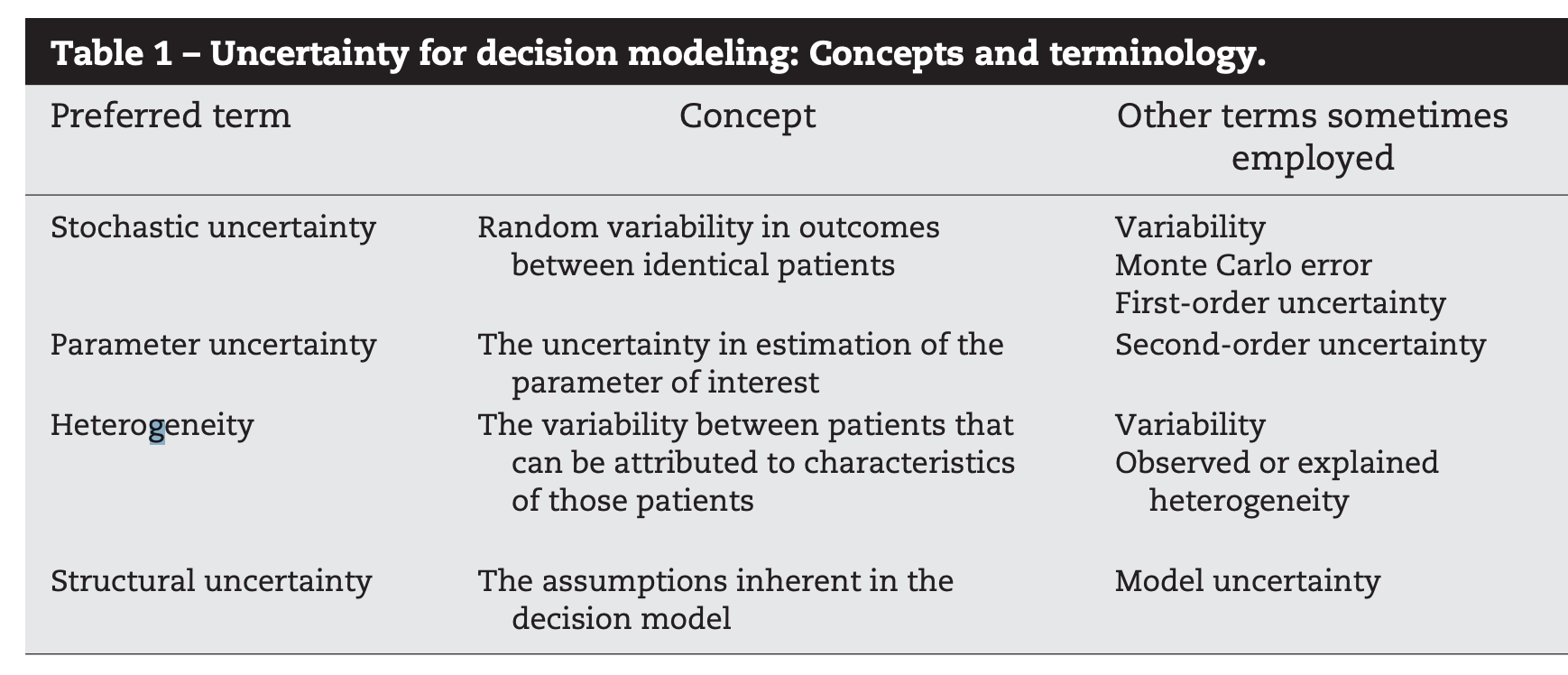
9. Systematic Approaches to Understanding Model Uncertainty
Heterogeneity vs. Uncertainty
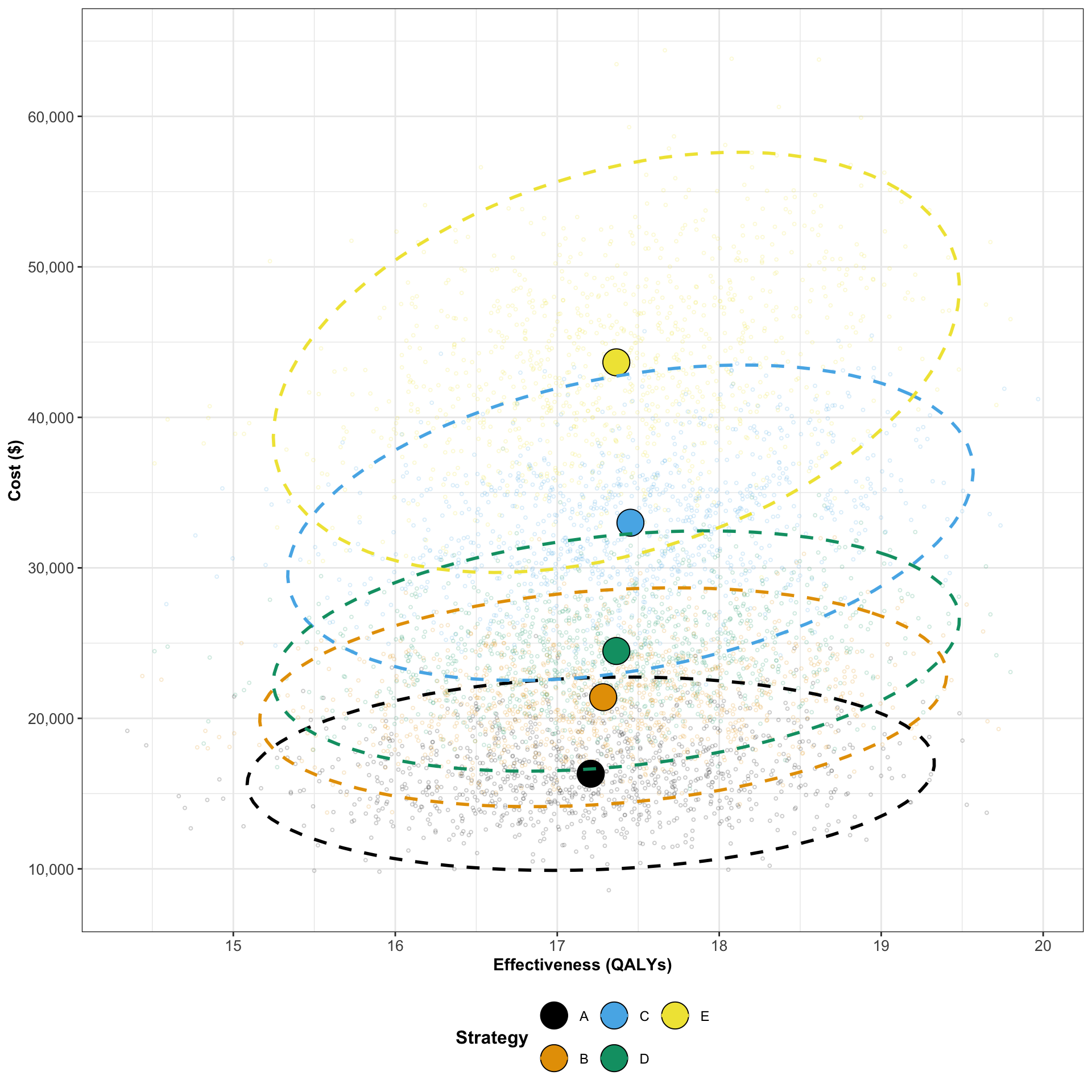
When Does Uncertainty Matter?

When Does Uncertainty Matter?

When Does Uncertainty Matter?

When Does Uncertainty Matter?

When Does Uncertainty Matter?
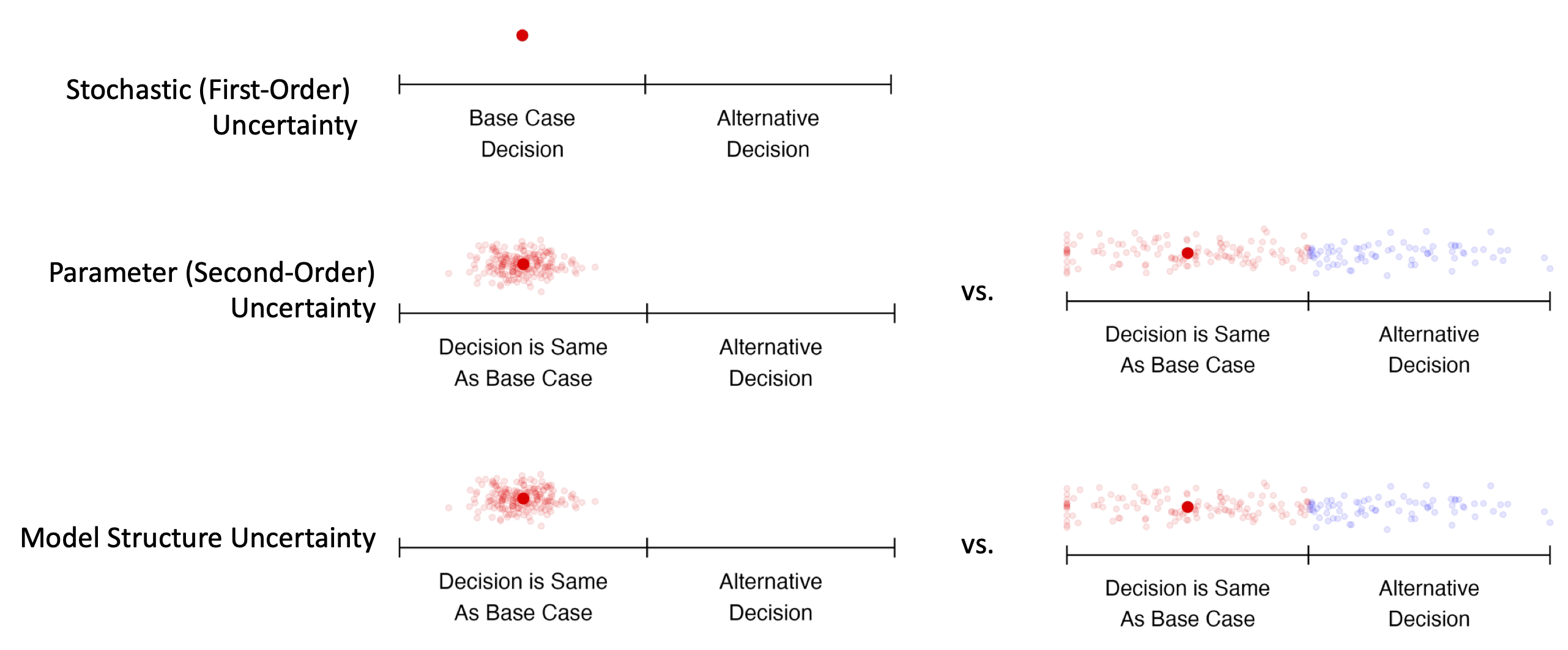
In this example, model outputs are sensitive to uncertainty, but decisions are not.

When Does Uncertainty Matter?
In this example, model outputs are sensitive to uncertainty, but decisions are not.

When Does Uncertainty Matter?
Both model outputs and decisions are sensitive to uncertainty.

When Does Uncertainty Matter?
Both model outputs and decisions are sensitive to uncertainty.

Markov Cohort Models
DES and Microsimulation
Probabilistic Sensitivity Analysis

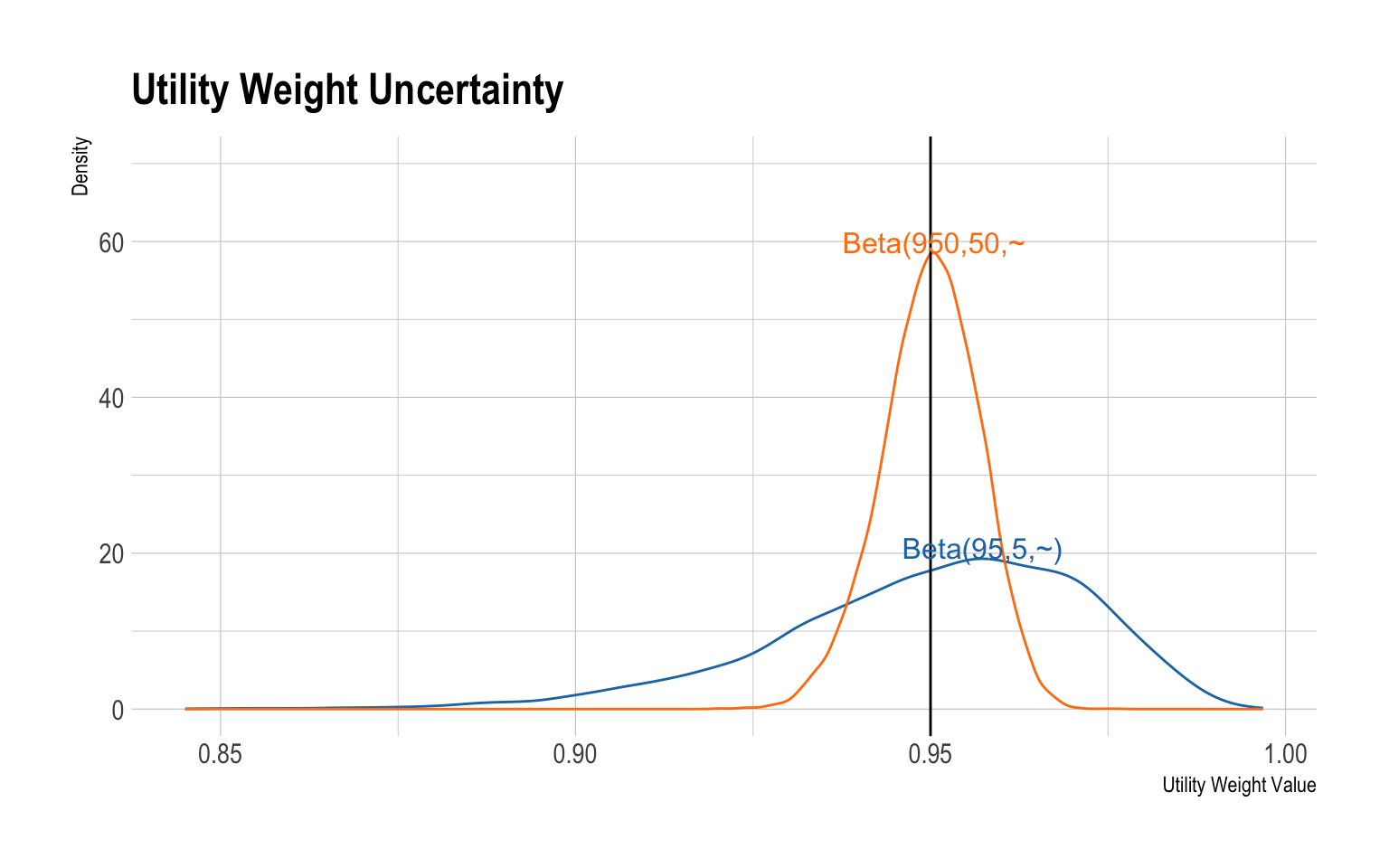
Exmample: Uncertainty in Utility Weight
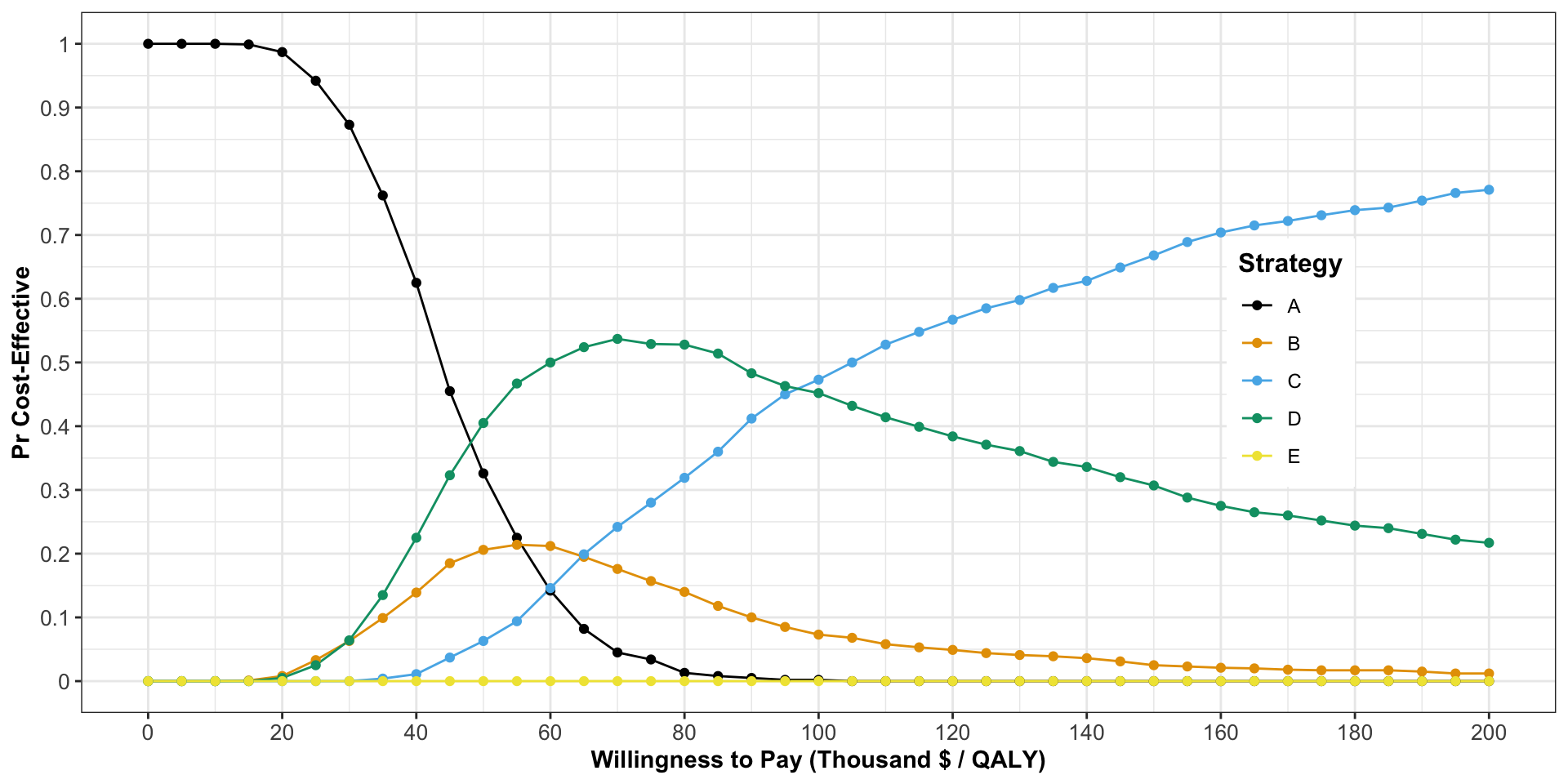
Cost Effectiveness Acceptability Curves
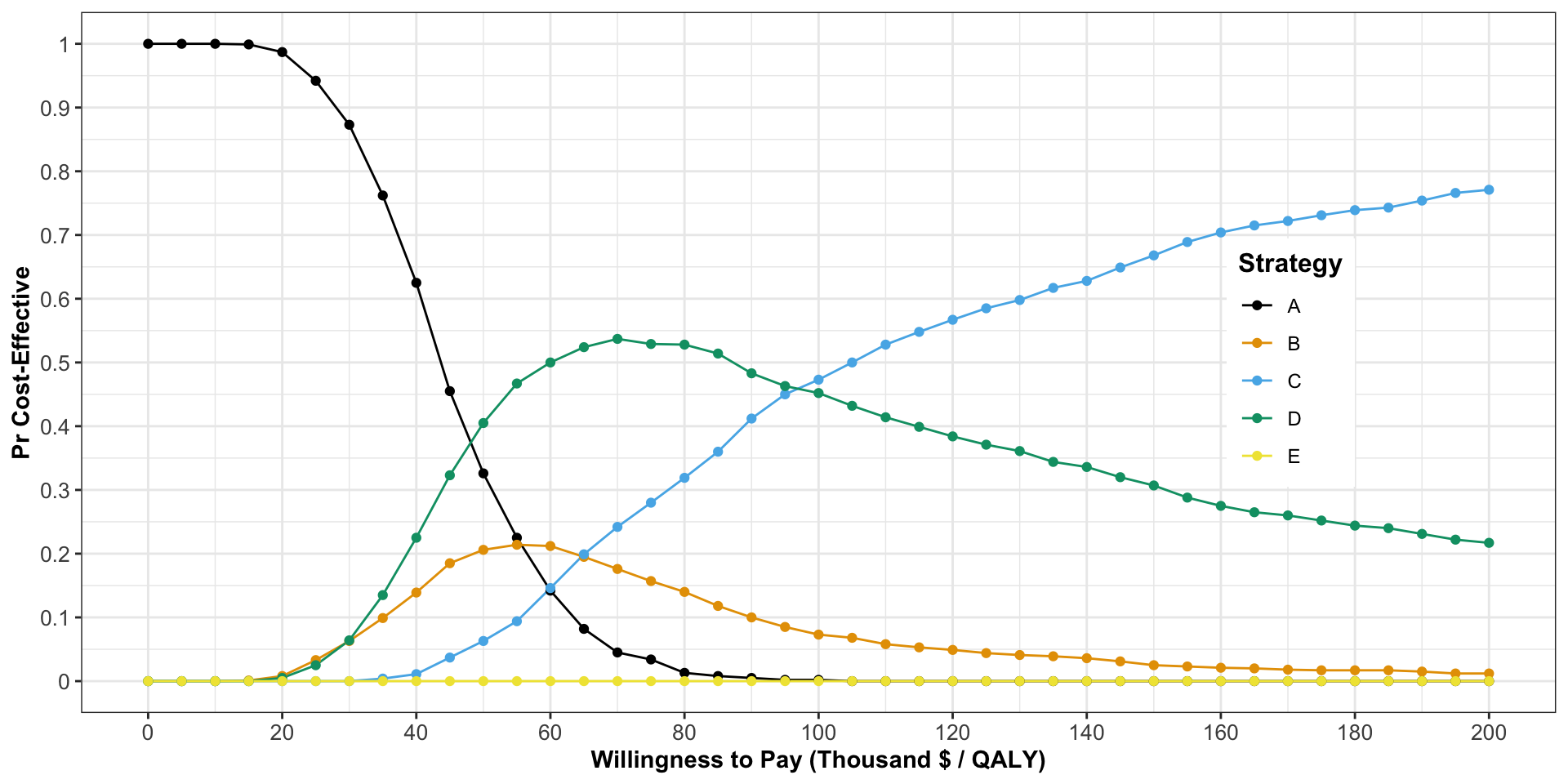
Cost Effectiveness Acceptability Curve (CEAC)
Cost Effectiveness Acceptability Frontier
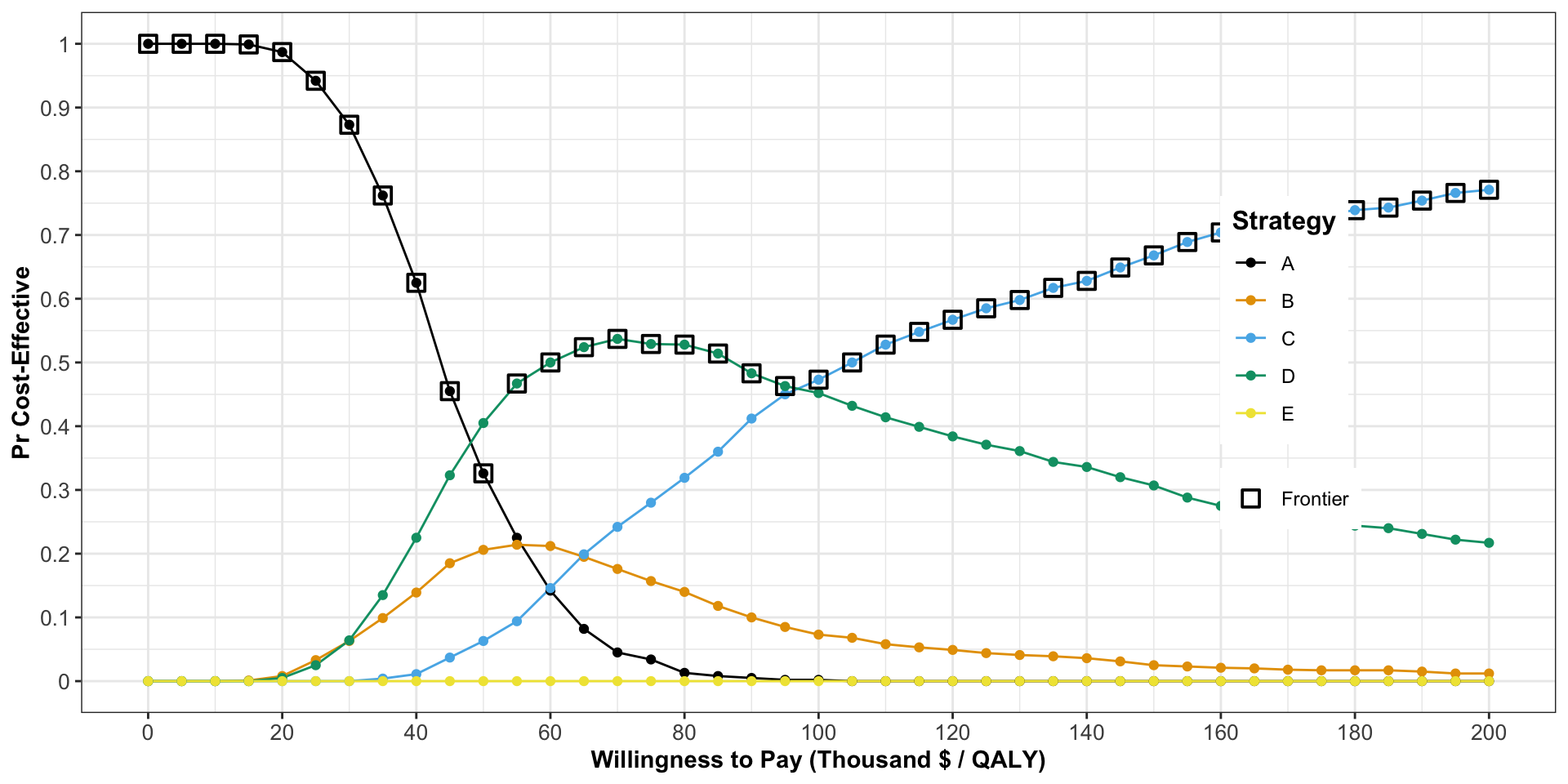
Cost Effectiveness Acceptability Frontier
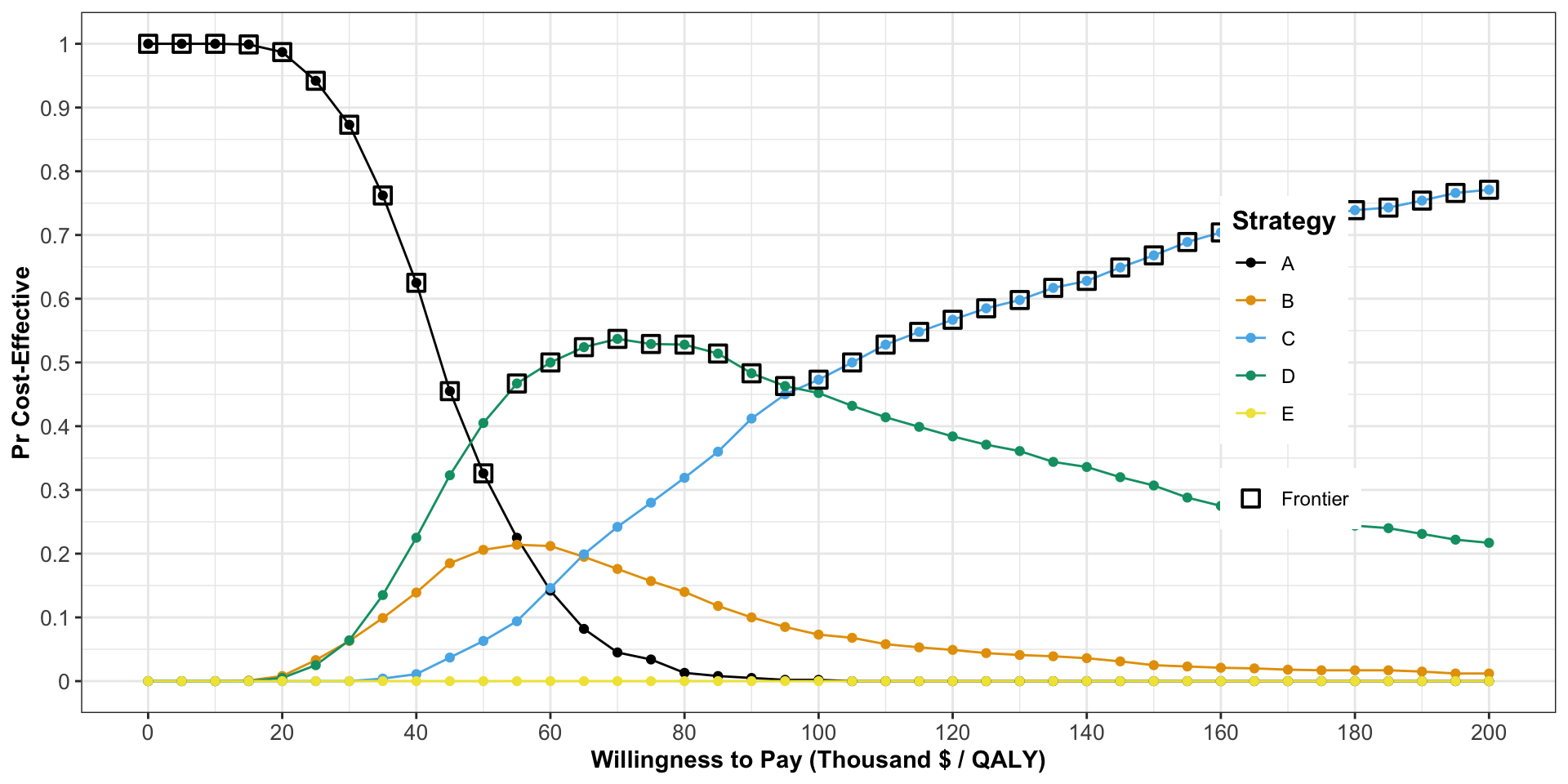
Expected Value of Perfect Information
- We will not cover VOI methods in detail here, but short courses are available.
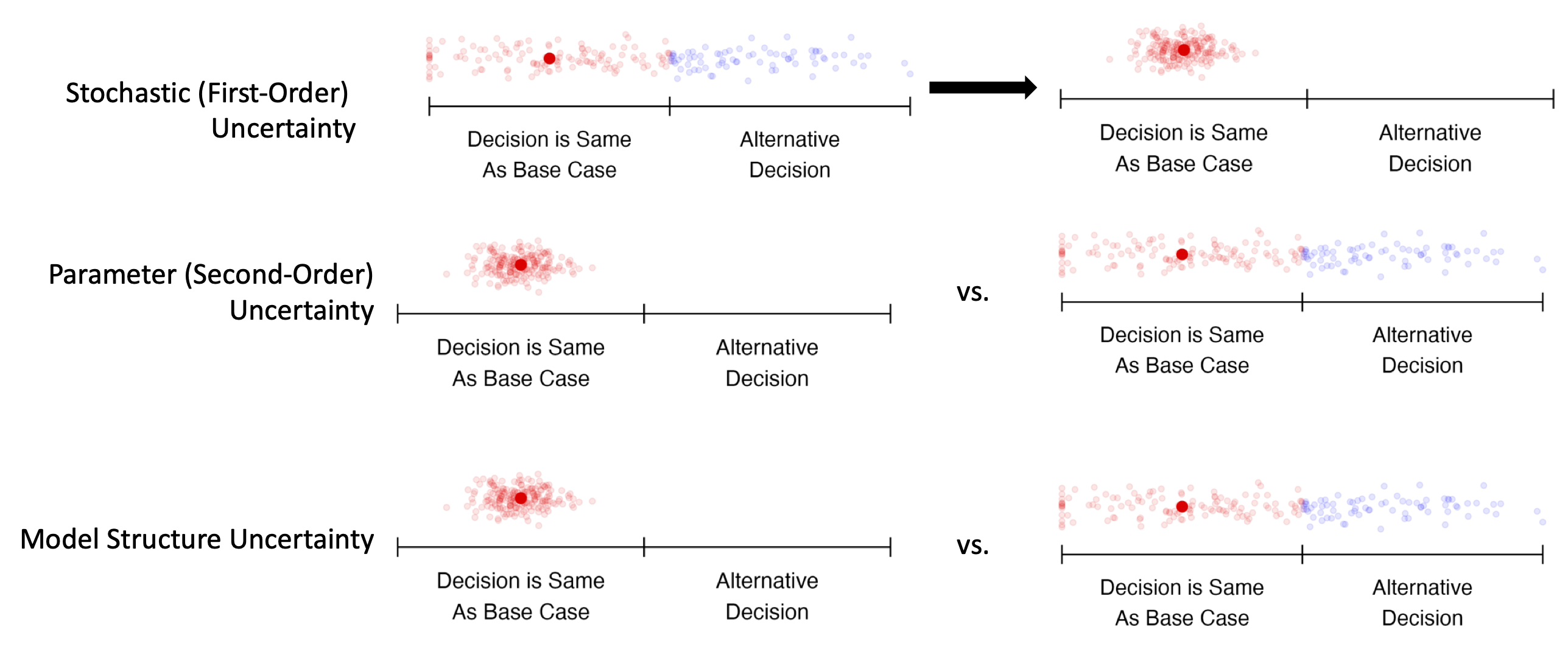
- Figure shows an instance where model is sensitive to uncertainty, but decisions are not.
- It’s not really worth pursuing additional research because we make the same decision regardless of the parameter values.

Expected Value of Perfect Information
- If decisions are sensitive to uncertainty, then the value of information is high.
- It may be worth pursuing additional research to reduce model parameter uncertainty.

Expected Value of Perfect Information
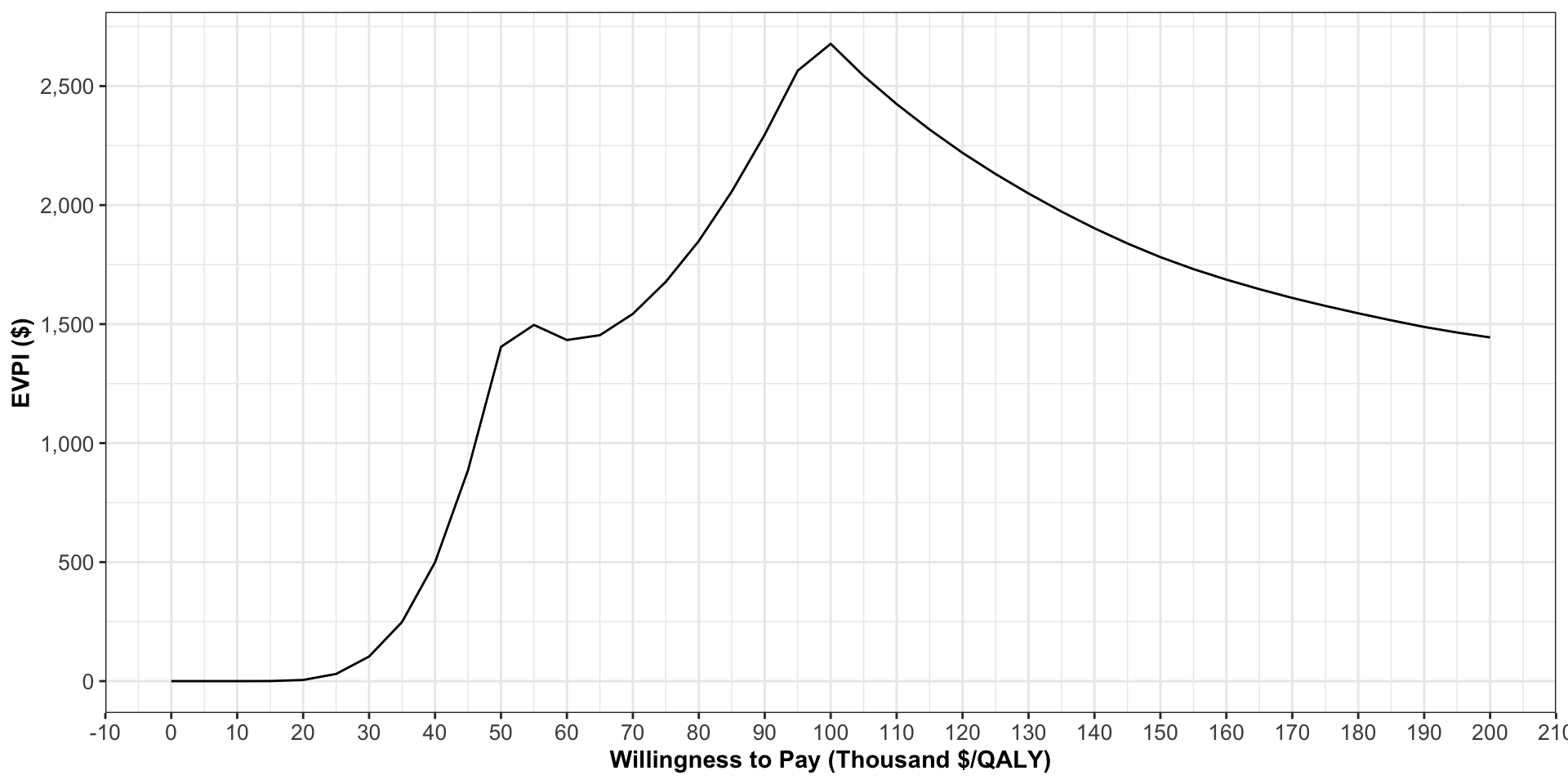
Expected Value of Perfect Information
- At \lambda=$100,000/QALY, there is high value of information.
- Our decision to implement one strategy over another is sensitive to uncertainty in our model.
Expected Value of Perfect Information
- At \lambda=$10,000/QALY, there is low value of information.
- Our decision to implement one strategy over another is not sensitive to uncertainty in our model.
Interactive Amua Session
